Копитко М.Ф. Основи інформаційних технологій (на укр. языке)
Подождите немного. Документ загружается.

наслідок, зумовлений різницею між первинним і вторинним
індексами, є такий:
• створювати розріджені вторинні індекси немає змісту,
оскільки вторинний індекс не впливає на фізичне положен-
ня записів у файлі даних і його не можна використовувати
як інструмент передбачення позиції довільного запису,
ключ якого не згадано у файлі індексу явно; вторинні
індекси завжди повинні бути щільними.
14.1. Проектування вторинних індексів
Вторинний індекс – це щільний індекс, який, зазвичай, містить
дублікати ключових значень. Як і раніше, індекс складається з пар
значень виду «ключ-покажчик». «Ключ» у цьому випадку – це
ключ пошуку, і вимоги щодо його унікальності не ставлять.
Елементи файла індексу посортовані за значеннями ключа – це дає
змогу пришвидшити пошук необхідного елемента. Якщо необхідно
доповнити структуру індексу другим рівнем, то лише розрідженим
– відповідні докази ми приводили у пункті 13.4.
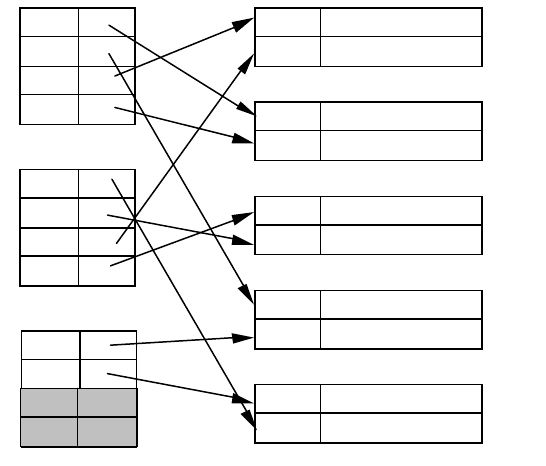
Приклад 49. На рис. 52 наведено типову структуру даних, яка
містить вторинний індекс. Відповідно до ухвалених нами
домовленостей блоки файла даних містять по два записи. На
рисунку зображено тільки значення ключових полів записів і ці
значення, як і раніше, кратні 10. Зауважте, що, на відміну від
файлів даних, розглянутих у пункті 13.5, файл даних у цьому
випадку не є посортованим за ключем пошуку. Проте елементи
файла індексу посортовані за значеннями ключа. Отож покажчики
в записах одного блока вторинного індексу здатні адресувати
найрізноманітніші блоки даних, а не один або декілька послідовних
блоків, як за умови використання первинного індексу. Наприклад,
щоб вийняти усі записи даних з ключем 20, доведеться не тільки
звернутися до двох блоків індексу, але й звернутися за відповід-
ними значеннями покажчиків до трьох різних блоків даних.
Отже, застосування вторинних індексів загалом вимагає
виконання значно більшої кількості операцій дискового
введення/виведення порівняно з тим, коли та ж кількість записів
даних є впорядкованою за допомогою первинного індексу. Проте
141
ми не можемо сподіватись на те, що порядок записів даних
виявиться саме таким, який необхідний, адже він може залежати
від інших атрибутів.
20
40
10
20
50
30
10
50
60
20
10
10
20
20
20
30
40
50
50
60
70
80
Рис. 52. Приклад структури з вторинним індексом
Цілком можливо доповнити структуру, подібну до наведеної на
рис. 52, другим рівнем індексу. Цей − розріджений − індекс
повинен містити елементи, які адресують найменші або найменші
нові значення ключів кожного блока даних (про це йшлося у
пункті 13.5).
14.2. Використання вторинних індексів
Крім забезпечення можливості швидкої обробки різних запитів
до відношень (або екземплярів класів), організованих у вигляді
послідовних файлів, вторинні індекси здатні виконувати корисні
функції і при використанні зі структурами інших типів, такими як
142
«купа» (heap), де записи даних розташовують у довільному
порядку.
Вторинні індекси часто використовують і для оптимізації
доступу до структур іншої категорії, які часто використовуються і
називаються компактно згрупованими файлами (clustered files).
Розглянемо відношення R і S, з’єднані зв’язком типу «багато до
одного», спрямованого від R до S. У деяких ситуаціях має сенс
зберігати кожен кортеж R спільно із зв’язаним кортежем S, а не
впорядковувати R за первинним ключем. Проілюструємо сказане
за допомогою реального прикладу.
Приклад 50. Звернемося до знайомих відношень «кінемато-
графічної» бази даних:
Movie (title, year, length, inColor, studioName, producerC#)
Studio (name, address, presC#)
Припустимо, що одним із «найпопулярніших» запитів є такий:
SELECT title, year
FROM Movie, Studio
WHERE presC# = zzz AND Movie.studioName =
Studio.name;
де zzz – деякий конкретний сертифікований номер президента
кіностудії. Отже, йдеться про відшукання інформації щодо всіх
фільмів, знятих на кіностудії, президентом якої є особа з заданим
сертифікованим номером.
Якщо такий запит дійсно належить до найтиповіших, тоді
замість впорядкування кортежів відношення Movie за значеннями
первинного ключа (title, year) доцільніше створити структуру
компактно згрупованого файла, яка об’єднує інформацію відно-
шень Studio і Movie так, як проілюстровано на рис. 53. Кожен
кортеж відношення Studio, що описує дані про деяку кіностудію,
супроводжує група кортежів відношення Movie, які представляють
відомості щодо усіх кінофільмів, випущених цією студією.
143

Студія 1 Студія 2 Студія 3
Студія 4
Фільми
студії 1
Фільми
студії 2
Фільми
студії 3
Фільми
студії 4
Рис. 53. Приклад компактно згрупованого файла
Якщо створити індекс для відношення Studio за ключем пошуку
presC#, то це даватиме змогу швидко відшукати кортеж з
інформацією про кіностудію для довільно заданого значення zzz.
Окрім того, всі кортежі-записи Movie, вміст компонентів
StudioName яких збігається зі значенням компонента name
кортежу Studio, розташовані у компактно згрупованому файлі
безпосередньо після відповідного запису Studio. Отож для
отримання даних про кінофільми, випущені певною студією,
достатньо буде виконати таку кількість операцій дискового
введення/виведення, яка близька до теоретичного мінімуму.
14.3. Додаткові рівні у вторинних індексах
Використання структури, наведеної на рис. 52, інколи пов’язане
з зайвими (і не малими) затратами дискового простору. Якщо
значення ключа пошуку присутнє у файлі даних n разів, то воно
стільки ж разів фігурує у файлі індексу. Було б доцільніше
зберігати тільки одну копію значення ключа спільно з усіма
покажчиками, які адресують записи даних, що володіють цим
ключем.
Щоб уникнути необхідності повторення ключових значень,
можна розмістити між вторинним індексом і файлом даних
додатковий рівень індексу, який складається із груп-сегментів
(buckets) покажчиків. Кожному відповідному значенню К ключа
пошуку відповідає єдиний елемент вторинного індексу, покажчик
якого адресує певну позицію у «файлі сегментів», де розташована
група покажчиків, що відповідають ключу К (рис. 54).
Приклад 51. Звернемось до структури, яку зображено на рис. 54,
і простежимо від елемента індексу з ключем пошуку 50 у напрямі
покажчика до відповідної позиції у проміжному «файлі сегментів».
144
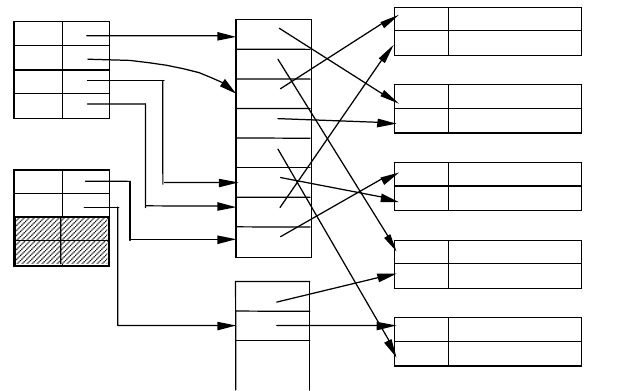
На цій позиції розміщений покажчик на запис даних, який займає
останнє місце в блоці файла сегментів. Наступний покажчик з тієї
ж групи розташований на початку другого блока файла сегментів, а
далі іде покажчик, який пов’язаний з іншим елементом (який
містить ключ 60) індексного файла. Отже, файл сегментів містить
групу з двох покажчиків, які посилаються на записи даних зі
значенням ключа пошуку, що дорівнює 50.
20
40
10
20
50
30
10
50
60
20
. . .
50
60
70
80
10
2
0
3
0
4
0
Файл індексу
Сегменти
Файл даних
Рис. 54. Додатковий рівень опосередкування у вторинному індексі
Схема, наведена на рис. 54, дає змогу зекономити простір на
диску тільки у тому випадку, коли значення ключа пошуку вимагає
більше місця, ніж вміст покажчиків, і повторюється не менше, ніж
два рази. Додатковий рівень опосередкування між вторинним
індексом і файлом даних, однак, обіцяє суттєві переваги і тоді, коли
досягти значної економії пам’яті не вдається: часто покажчики у
файлі сегментів можуть допомогти системі обробити запит з
мінімальною кількістю звернень до файла даних. Зокрема, якщо
запит містить декілька умов і кожній з них відповідає певний
145

вторинний індекс, то шляхом операції пошуку перетину множини
покажчиків в оперативній пам’яті можна виявити покажчики, які
задовольняють водночас усі умови, і обмежити набір записів, які
зчитуються, тільки тими, які адресуються покажчиками
результуючої множини. Отож системі вдасться уникнути витрат,
пов’язаних із завантаженням записів, що задовольняють деяким,
однак не всім, умовам
2
.
Приклад 52. Розглянемо відношення:
Movie (title, year, length, inColor, studioName, producerC#)
із «кінематографічної» бази даних. Припустимо, що створені
вторинні індекси з проміжними сегментами для значень атрибутів
studioName і year і необхідно отримати відповідь на запит
SELECT title, year
FROM Movie
WHERE studioName = ‘Disney’ AND year = 1995;
який має відшукати інформацію про всі кінофільми, випущені
студією «Disney» у 1995 році.
На рис. 55 наведено схему дій, необхідних для опрацювання
запиту із залученням вторинних індексів. За допомогою індексу
для атрибута studioName можна швидко знайти покажчики на всі
записи, що відповідають кінофільмам студії «Disney» (зауважте,
що йдеться тільки про покажчики – жодного запису ще не заванта-
жено в ОП). У свою чергу, індекс для атрибута year сприятиме
виявленню покажчиків на записи з описом усіх кінофільмів, які
вийшли на екрани у 1995 році. Тепер достатньо виконати операцію
перетину двох множин покажчиків, щоб виявити саме ті із них, які
відповідають записам про кінофільми студії «Disney», зняті у 1995
році, а потім завантажити в пам’ять усі блоки даних (і тільки такі
2
Трюк з перетином множини покажчиків можна використовувати і в
тому випадку, коли покажчики розташовані у файлі індексу, а не у
проміжних групах-сегментах. Однак наявність файла сегментів часто
знижує витрати на операції дискового введення-виведення, оскільки
покажчики менш об’ємні, ніж пари «ключ-покажчик» індексу.
146
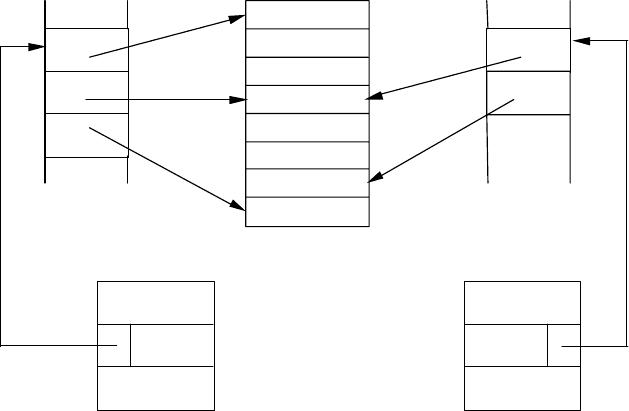
блоки), що містять записи, які адресуються покажчиками
підсумкової множини.
Disney
1995
Сегменти для
studioName
Кортежі відношення
Movie
Сегменти для
year
Рис. 55. Перетин множин покажчиків в ОП
14.4. Пошук документів і звернені індекси
Протягом тривалого часу користувачі інформації були стурбо-
вані проблемами ефективного пошуку документів за заданою
множиною ключових слів. З приходом технологій Word Wide Web,
які забезпечують можливість доступу до документів у режимі on-
line, ці проблеми загострюються, отож заслуговують на підвищену
увагу. Для відшукання відповідних документів користувачі
застосовують найрізноманітніші запити. Найпростішу і поширену
форму подібних запитів можна представити наступним способом.
• Інформація, яка описує документ, трактується як кортеж
деякого відношення Doc. Відношення має дуже велику
147
кількість атрибутів, по одному на кожне слово в документі.
Кожен атрибут зачислено до логічного типу. Компонент
атрибуту засвідчує, чи присутнє відповідне слово у
документі, чи ні. Приклад схеми відношення Doc виглядає
так:
Doc (hasCat, hasDog, …), де компонент, подібний до
hasCat, має значення
TRUE, якщо і тільки якщо документ
містить у крайньому випадку один екземпляр відповідного
слова (у нашому випадку –cat).
• Кожен атрибут відношення Doc має вторинний індекс;
індекс містить тільки такі елементи, які відповідають
значенням TRUE ключа пошуку, тобто вказують на
документи, які містять певне слово.
• Усі індекси об’єднуються в одному, зверненому (inverted),
індексі. Звернений індекс використовується спільно з
проміжним рівнем груп-сегментів покажчиків.
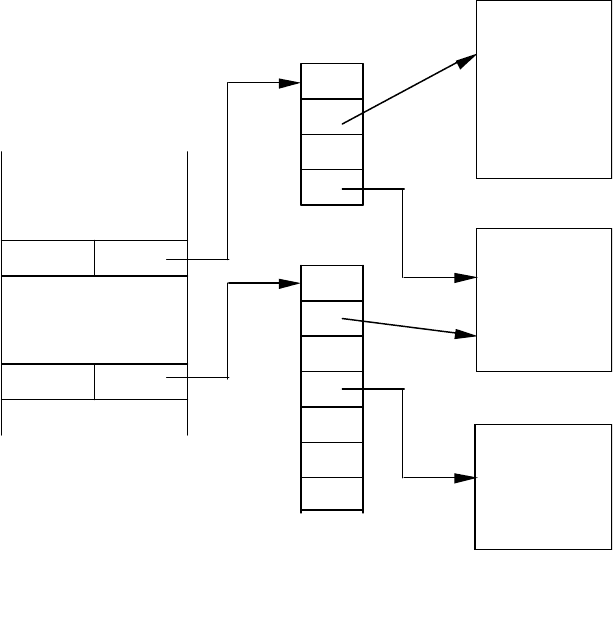
Приклад 53. Спосіб застосування зверненого індексу проілю-
стровано на рис. 56. На місці файла із записами використано
колекцію документів, кожен з яких зберігається в одному або
декількох дискових блоках. Звернений індекс сформовано з
множини пар вигляду «слово-покажчик»». Слова виконують
функцію значень ключа пошуку. Звернений індекс, як і будь-який
інший індекс, міститься в послідовних блоках. Однак у
застосуваннях, які стосуються пошуку документів, інформація
більш статична, ніж вміст звичайних баз даних. Отож ситуації, що
передбачають необхідність створення блоків переповнення або
зміни індексу, виникають рідше.
Покажчики в елементах індексу адресують позиції «файла
сегментів». На рис. 56, наприклад, покажчик запису індексу з
ключовим словом cat посилається на початок групи покажчиків, які
адресують документи, що містять у своєму складі слово cat. На
рисунку символічно представлено деякі з таких документів.
Аналогічно, елемент з ключем dog спрямований до групи
покажчиків, які посилаються на документи зі словом dog.
148
ca
t
dog
…When
the cat is
away, the
mice will
play …
. . . as
a cat
with
a dog …
…Barking
dogs
seldom
bite…
Звернений
індекс
Сегменти
Документи
Рис. 56. Пошук документів за допомогою зверненого індексу
9 Корисно знати. Дещо про пошук інформації
за ключовими словами. Існує чимало прийомів,
які сприяють підвищенню ефективності процедур
пошуку документів за ключовими словами. Хоча
детальне висвітлення предмета виходить за
рамки тексту лекцій, однак два корисних
методи подамо.
1. Виділення кореневої основи слів.
Перед включенням в індекс кожне слово під-
дається обробці, яка передбачає вилучення
префіксів, суфіксів і закінчень, а також
149
виконання інших необхідних дій. Наприклад,
іменники у множині приводять до однини
(цей прийом використано у структурі, зо-
браженій на рис. 56, оскільки процес
пошуку за ключовим словом «dog» приводить
до отримання документів, які містять не
тільки слово «dog», але й відповідний
варіант множини – «dogs»).
2. Відкидання слів-роздільників. Спо-
лучники, частки, артиклі, прийменники та
інші подібні слова, які часто використо-
вуються, і не несуть особливого змістового
навантаження і є присутніми практично у
будь-якому документі, зі зверненого індек-
су, зазвичай, вилучаються. Вилучення слів-
роздільників не впливає на якість резуль-
татів пошуку і дає змогу суттєво зменшити
розміри файла індексу і час, необхідний
для його перегляду.
Файл сегментів може містити:
1) покажчики на документи загалом;
2) покажчики, які посилаються на екземпляри ключового слова
всередині документа; у цьому випадку покажчик може
складатися з двох частин – адреси першого блока документа і
цілочислового номера слова у документі.
За використання другого варіанта, що передбачає застосування
покажчиків, які адресують окремі входження ключового слова в
тексті документа, модель файла сегментів може бути розширеною
за рахунок додаткової інформації про кожен екземпляр ключового
слова всередині документа. Тепер файл сегментів сам по собі стає
колекцією записів достатньо складної структури. Перші реалізації
подібної моделі давали змогу розрізняти зразки ключового слова,
присутні у назві, анотації і тілі документа. З розвитком технологій
опису Web-документів засобами HTML, XML та інших мов
розмітки стало можливим задавати і різні ознаки формування
ключових слів, які необхідно відшукати. Тепер система здатна
зовсім незалежно розрізняти слова, які присутні в назвах,
заголовках, таблицях, фрагментах «звичайного» тексту або рядках
150