Гордеев А.В. Операционные системы
Подождите немного. Документ загружается.


242 Глава 7, Организация параллельных взаимодействующих вычислений
SEND_ANSWER ( Результат, Ответ, Буфер )
Эта операция записывает информацию, определяемую через переменную Ответ
в тот буфер, номер которого указывается переменной Буфер (из этого буфера
было получено сообщение), и добавляет буфер к очереди отправителя. Если
отправитель ждет ответ, он деблокируется.
WAIT_ANSWER ( Результат, Ответ, Буфер ) .
Эта операция блокирует процесс, выдавший операцию, до тех пор, пока в буфер
не поступит ответ; доступ к нему возможен через переменную Буфер. После того
как ответ поступил и процесс передан на процессор, ответ, доступ к которому
определяется через переменную Ответ, переписывается в память процессу, а
буфер освобождается. Значение переменной Результат указывает, является ли
ответ пустым, то есть выданным операционной системой, так как сообщение
было адресовано несуществующему (или так и не ставшему активным) процессу.
Основные достоинства почтовых ящиков:
• процессу не нужно знать о существовании других процессов до тех пор, пока он
не получит сообщения от них;
Q два процесса могут обменяться более чем одним сообщением за один раз;
а операционная система может гарантировать, что никакой иной процесс не вме-
шается во взаимодействие процессов, ведущих между собой «переписку»;
• очереди буферов позволяют процессу-отправителю продолжать работу, не об-
ращая внимания на получателя.
Основным недостатком буферизации сообщений является появление еще одного
ресурса, которым нужно управлять. Этим ресурсом являются сами почтовые ящики.
К другому недостатку можно отнести статический характер этого ресурса: количество
буферов для передачи сообщений через почтовый ящик фиксировано. Поэтому есте-
ственным стало появление механизмов, подобных почтовым ящикам, но реализован-
ных на принципах динамического выделения памяти под передаваемые сообщения.
В операционных системах компании Microsoft тоже имеются почтовые ящики
(mailslots). В частности, они достаточно часто используются при создании распре-
деленных приложений для сети. При работе с ними в приложении, которое долж-
но отправить сообщение другому приложению, необходимо указывать класс дос-
тавки сообщений. Различают два класса доставки. Первый класс (first-class delivery)
гарантирует доставку сообщений; он ориентирован на сеансовое взаимодействие
между процессами и позволяет организовать посылки типа «один к одному» и «один
ко многим». Второй класс (second-class delivery) основан на механизме датаграмм,
и он уже не гарантирует доставку сообщений получателю.
Конвейеры и очереди сообщений
Конвейеры
Программный канал связи (pipe), или, как его иногда называют, конвейер, транс
портер, является средством, с помощью которого можно обмениваться данны
между процессами. Принцип работы конвейера основан на механизме ввода-вы-
яода файлов в UNIX, то есть задача, передающая информацию, действует так, как
будто она записывает данные в файл, в то время как задача, для которой предна-
значается эта информация, читает ее из этого файла. Операции записи и чтения
осуществляются не записями, как это делается в обычных файлах, а потоком бай-
тов, как это принято в UNIX-системах. Таким образом, функции, с помощью кото-
рых выполняется запись в канал и чтение из него, являются теми же самыми, что и
при работе с файлами. По сути, канал представляет собой поток данных между
двумя (или более) процессами. Это упрощает программирование и избавляет про-
граммистов от использования каких-то новых механизмов. На самом деле конвей-
еры не являются файлами на диске, а представляют собой буферную память, рабо-
тающую по принципу FIFO, то есть по принципу обычной очереди. Однако не
следует путать конвейеры с очередями сообщений; последние реализуются иначе
и имеют другие возможности.
Конвейер имеет определенный размер
1
, который не может превышать 64 Кбайт и
работает циклически. Вспомните реализацию очереди на массивах, когда имеются
указатели начала и конца очереди, которые перемещаются циклически по массиву.
То есть имеется некий массив и два указателя: один показывает на первый элемент
(указатель на начало — head), а второй — на последний (указатель на конец — tail).
В начальный момент оба указателя равны нулю. Добавление самого первого эле-
мента в пустую очередь приводит к тому, что указатели на начало и на конец при-
нимают значение, равное 1 (в массиве появляется первый элемент). В последую-
щем добавление нового элемента вызывает изменение значения второго указателя,
поскольку он отмечает расположение именно последнего элемента очереди. Чте-
ние (и удаление) элемента (читается и удаляется всегда первый элемент из со-
зданной очереди) приводит к необходимости модифицировать значение указате-
ля на ее начало. В результате операций записи (добавления) и чтения (удаления)
элементов в массиве, моделирующем очередь элементов, указатели будут переме-
щаться от начала массива к его концу. При достижении указателем значения ин-
декса последнего элемента массива значение указателя вновь становится единич-
ным (если при этом не произошло переполнение массива, то есть количество
элементов в очереди не стало большим числа элементов в массиве). Можно ска-
зать, что мы как бы замыкаем массив в кольцо, организуя круговое перемещение
указателей на начало и на конец, которые отслеживают первый и последний эле-
менты в очереди. Сказанное иллюстрирует рис. 7.4. Именно так функционирует
конвейер.
Как информационная структура конвейер описывается идентификатором, разме-
ром и двумя указателями. Конвейеры представляют собой системный ресурс. Чтобы
начать работу с конвейером, процесс сначала должен заказать его у операционной
системы и получить в свое распоряжение. Процессы, знающие идентификатор кон-
Ве
Нера, могут через него обмениваться данными.
Механизм конвейеров, впервые введенный в UNIX-системах, имеет максимальный размер 64 Кбайт,
оскольку в 16-разрядных мини-ЭВМ, для которых создавалась эта ОС, нельзя было иметь массив
ванных большего размера.

244 Глава 7. Организация параллельных взаимодействующих вычисление
А
Указатель на начало
А
Указатель на конец
I—^—
й
Указатель на конец Указатель на начало
Рис. 7.4. Организация очереди в массиве
В качестве иллюстрации приведем основные системные запросы для работы с кон-
вейерами, которые имеются в API OS/2.
• Функция создания конвейера:
OosCreatePipe (SReadHandle, &WriteHandle. PipeSize):
Здесь ReadHandle — дескриптор чтения из конвейера, Write На nd le —
дескриптор записи в конвейер, PipeSize — размер конвейера.
• Функция чтения из конвейера:
"DosRead (SReadHandle. (PVOID)&Inform. sizeof(Inform), SBytesRead):
Здесь ReadHandle — дескриптор чтения из конвейера, Inform — переменная
любого типа, sizeof(Inform) — размер переменной Inform, BytesRead —
количество прочитанных байтов. Данная функция при обращении к
пустому конвейеру будет ожидать, пока в нем не появится информация
для чтения.
• Функция записи в конвейер:
DosWrite (SWriteHandle, (PVOID)SInform. sizeof(Inform). SBytesWrite):
Здесь WriteHandle — дескриптор записи в конвейер, BytesWrite — количество
записанных байтов.
Читать из конвейера может только тот процесс, который знает идентификатор со-
ответствующего конвейера. При работе с конвейером данные непосредственно
помещаются в него. Еще раз отметим, что из-за ограничения на размер конвейера
программисты сталкиваются и с ограничениями на размеры передаваемых через
него сообщений.
Очереди сообщений
Очереди (queues) сообщений предлагают более удобный метод связи между взаи-
модействующими процессами по сравнению с каналами, но в своей реализаЦИ
они сложнее. С помощью очередей также можно из одной или нескольких задач
независимым образом посылать сообщения некоторой задаче-приемнику. При это*
только процесс-приемник может читать и удалять сообщения из очереди, а про

конвейеры и очереди сообщений
24Э
цессы-клиенты имеют право лишь помещать в очередь свои сообщения. Таким
образом, очередь работает только в одном направлении. Если же необходима
двухсторонняя связь, то можно создать две очереди.
работа с очередями сообщений отличается от работы с конвейерами. Во-первых,
оЧ
ереди сообщений предоставляют возможность использовать несколько дисцип-
лин обработки сообщений:
р FIFO — сообщение, записанное первым, будет первым и прочитано;
• LIFO — сообщение, записанное последним, будет прочитано первым;
р приоритетный доступ — сообщения читаются с учетом их приоритетов;
р произвольный доступ — сообщения читаются в произвольном порядке.
Тогда как канал обеспечивает только дисциплину FIFO.
Во-вторых, если при чтении сообщения оно удаляется из конвейера, то при чтении
сообщения из очереди этого не происходит, и сообщение при желании может быть
прочитано несколько раз.
В-третьих, в очередях присутствуют не непосредственно сами сообщения, а толь-
ко их адреса в памяти и размер. Эта информация размещается системой в сег-
менте памяти, доступном для всех задач, общающихся с помощью данной оче-
реди.
Каждый процесс, использующий очередь, должен предварительно получить раз-
решение на доступ в общий сегмент памяти с помощью системных запросов API,
ибо очередь — это системный механизм, и для работы с ним требуются системные
ресурсы и, соответственно, обращение к самой ОС. Во время чтения из очереди
задача-приемник пользуется следующей информацией:
Q идентификатор процесса (Process Identifier, PID), который передал сообщение;
• адрес и длина переданного сообщения;
• признак необходимости ждать, если очередь пуста;
• приоритет переданного сообщения;
• номер освобождаемого семафора, когда сообщение передается в очередь.
Наконец, приведем перечень основных функций, управляющих работой очереди
(без подробного описания передаваемых параметров, поскольку в различных ОС
обращения к этим функциям могут существенно различаться):
Q
CreateQueue — создание новой очереди;
Q
OpenQueue — открытие существующей очереди;
а
ReadQueue — чтение и удаление сообщения из очереди;
u
PeekQueue — чтение сообщения без его последующего удаления из очереди;
WriteQueue — добавление сообщения в очередь;
CbseQueue — завершение использования очереди;
Q p
urgeQue ue — удаление из очереди всех сообщений;
UueryQueue — определение числа элементов в очереди.

246 Глава 7. Организация параллельных взаимодействующих вычислений
Контрольные вопросы и задачи
1. Какие последовательные вычислительные процессы мы называем параллель-
ными и почему? Какие параллельные процессы называются независимыми
а какие — взаимодействующими?
2. Изложите алгоритм Деккера, позволяющий разрешить проблему взаимного
исключения путем использования одной только блокировки памяти.
3. Объясните, как действует команда проверки и установки. Расскажите о рабо-
те команд BTS и BTR, которые имеются в процессорах с архитектурой ia32.
4. Расскажите о семафорах Дейкстры. Чем обеспечивается взаимное исключе-
ние при выполнении примитивов Р и V?
5. Изложите, как могут быть реализованы семафорные примитивы для мульти-
процессорной системы?
6. Что такое мыотекс?
7. Изложите алгоритм решения задачи «поставщик-потребитель» при исполь-
зовании семафоров Дейкстры.
8. Изложите алгоритм решения задачи «читатели-писатели» при использова-
нии семафоров Дейкстры.
9. Что такое «монитор Хоара»? Приведите пример такого монитора.
10. Что представляют собой почтовые ящики?
11. Что представляют собой конвейеры (программные каналы)?
12. Что представляют собой очереди сообщений? Чем отличаются очереди сооб-
щений от почтовых ящиков?
Глава 8. Проблема тупиков
и методы борьбы с ними
Рассмотрим одну из самых серьезных и трудноразрешимых проблем, возникаю-
щих при организации мультипрограммного режима работы, — проблему тупиков
и основные подходы при борьбе с ними. В этой главе представлены некоторые
модели параллельных вычислительных процессов, позволяющие проводить их
анализ в аспекте корректного решения указанных проблем.
Понятие тупиковой ситуации
при выполнении параллельных
вычислительных процессов
*»
При организации параллельного выполнения нескольких вычислительных про-
цессов одной из главных функций операционной системы является решение слож-
ной задачи корректного распределения ресурсов между выполняющимися процес-
сами и обеспечение последних средствами взаимной синхронизации и обмена
данными.
При параллельном исполнении процессов могут возникать тупиковые ситуации,
когда два или более процесса блокируют друг друга, вынуждая ожидать наступле-
ния события, связанного с освобождением ресурса. Самым простым является слу-
чай, когда каждый из двух процессов ожидает ресурс, занятый другим процессом.
Из-за такого ожидания ни один из процессов не может продолжить исполнение
и освободить в конечном итоге ресурс, необходимый другому процессу. Эта ситу-
ация называется тупиком, дедлоком (dead lock
1
), или клинчем. Говорят, что в муль-
типрограммной системе процесс находится в состоянии тупика, если он ждет
события, которое никогда не произойдет. Тупики чаще всего возникают из-за кон-
куренции несвязанных параллельных процессов за ресурсы вычислительной сис-
темы, но иногда к тупикам приводят и ошибки программирования взаимодейству-
ющих вычислений.
Uead lock (англ.) — смертельное объятие.

248 Глава 8. Проблема тупиков и методы борьбы с нимц
При рассмотрении проблемы тупиков целесообразно понятие ресурсов системы
обобщить и разделить их все на два класса:
Q повторно используемые (Reusable Resource, RR), или системные (System Re-
source, SR), ресурсы;
• потребляемые, или расходуемые, ресурсы (Consumable Resource, CR).
Системные ресурсы (SR) есть конечное множество идентичных единиц некоторо-
го вида ресурсов, обладающих следующими свойствами [54]:
• число единиц ресурса в системе неизменно;
• каждая единица ресурса либо доступна, либо выделена одному и только одно-
му процессу (разделение отсутствует или не принимается во внимание, так как
не оказывает влияния на распределение ресурсов, а значит, и на возникновение
тупиковой ситуации);
• процесс может освободить единицу ресурса (сделать ее доступной), только если
он ранее получил эту единицу, то есть никакой процесс не может оказывать
влияние на ресурс, если этот ресурс ему не принадлежит.
Данное определение выделяет существенные для изучения проблемы тупика свой-
ства системных ресурсов, к которым мы относим компоненты аппаратуры, такие
как основная память, вспомогательная (внешняя) память, периферийные устрой-
ства и, возможно, процессоры, а также программное и информационное обеспече-
ние, такое как файлы данных, таблицы и «разрешение войти в критическую сек-
цию».
Расходуемые ресурсы (CR) отличаются от ресурсов типа SR в нескольких важных
отношениях [17].
Q Число доступных единиц некоторого ресурса типа CR изменяется по мере того,
как выполняющимися процессами они расходуются (приобретаются) и осво-
бождаются (производятся). В общем случае число единиц расходуемых ресурсов
является потенциально неограниченным, поскольку некий процесс «произ-
водитель» может достаточно долго увеличивать число единиц ресурса, осво-
бождая одну или более единиц, которые он «создал».
Q Процесс «потребитель» уменьшает число единиц ресурса, сначала запрашивая
и затем приобретая (потребляя) одну или более единиц. Единицы ресурса, ко-
торые приобретены, в общем случае не возвращаются ресурсу, а потребляются
(расходуются). Эти свойства потребляемых ресурсов присущи многим синхро-
низирующим сигналам, сообщениям и данным, порождаемым как аппаратурой,
так и программным обеспечением, и могут рассматриваться как ресурсы типа
CR при изучении тупиков. В их число входят: прерывания от таймера и уст-
ройств ввода-вывода; сигналы синхронизации процессов; сообщения, содержа
щие запросы на различные виды обслуживания или данные, а также соответ-
ствующие ответы.
Для исследования параллельных процессов и, в частности, проблемы тупиков было
разработано несколько моделей. Одной из них является модель повторно использу
мых ресурсов Холта [54]. Согласно этой модели система представляется как на о
(множество) процессов и набор ресурсов, причем каждый из ресурсов состоит
Ппимеры тупиковых ситуаций и причины их возникновения
249
, состояние системы
фиксированного числа единиц. Любой процесс может изменять <
путем выдачи запроса на получение или освобождение единицы ресурса.
В графической форме процессы и ресурсы представляются квадратами и кружка-
ми соответственно. Каждый кружок содержит некоторое количество маркеров
(фишек) в соответствии с существующим количеством единиц этого ресурса. Дуга,
указывающая из «процесса» на «ресурс», означает запрос одной единицы этого
ресурса. Дуга, указывающая из «ресурса» на «процесс», представляет выделение
ресурса процессу. Поскольку каждая единица любого ресурса типа SR может быть
выделена одновременно не более чем одному процессу, то число дуг, исходящих
из ресурса к различным процессам, не может превышать общего числа единиц это-
го ресурса. Такая модель называется графом повторно используемых ресурсов.
Пример одного из состояний системы из двух процессов с ресурсами типа SR пред-
ставлен на рис. 8.1.
Пр2
Пр1
R2
Рис. 8.1. Пример модели Холта
Пусть процесс Пр1 запрашивает две единицы ресурса R1 и одну единицу ресурса
R2. Процессу Пр2 принадлежат две единицы ресурса R1, и ему нужна одна едини-
ца R2. Предположим, что процесс Пр1 получил запрошенную им единицу R2. Если
принято правило, по которому процесс должен получить все запрошенные им ре-
сурсы прежде, чем освободить хотя бы один из них, то удовлетворение запроса
Пр1 приведет к тупиковой ситуации: Пр1 не сможет продолжиться до тех пор, пока
Пр2 не освободит единицу ресурса R1, а процесс Пр2 не сможет продолжиться до
тех пор, пока Пр1 не освободит единицу R2. Причиной этого тупика являются не-
упорядоченные попытки процессов войти в критическую секцию, связанную с вы-
делением соответствующей единицы ресурса.
Примеры тупиковых ситуаций
и
причины их возникновения
я
понимания основных причин возникновения тупиков рассмотрим несколько
Р°стых характерных примеров.
250
Глава 8. Проблема тупиков и метЬды борьбыс ними
Пример тупика на ресурсах типа CR
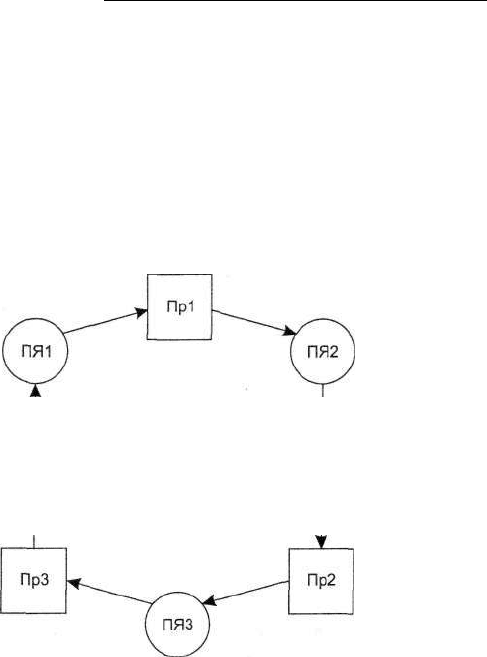
Пусть имеется три процесса Пр1, Пр2 и ПрЗ, которые вырабатывают сообщения
Ml, M2 и МЗ соответственно. Эти сообщения представляют собой ресурсы типа
CR. Пусть процесс Пр1 является потребителем сообщения МЗ, процесс Пр2 дол-
жен получить сообщение Ml, а ПрЗ ожидает сообщение М2 от процесса Пр2. Та-
ким образом, каждый из этих трех процессов является и поставщиком, и потреби-
телем одновременно, и вместе они образуют кольцевую систему (рис. 8.2) передачи
сообщений через почтовые ящики (ПЯ).
Рис. 8.2. Кольцевая схема взаимодействия процессов
Если связь с помощью этих сообщений со стороны каждого процесса устанавлива-
ется в порядке, представленном в листинге 8.1, то никаких проблем не возникает.
Однако перестановка этих двух процедур в каждом из процессов вызывает тупик
(листинг 8.2).
Листинг 8.1. Вариант псевдокода без тупиковой ситуации
Пр1:
ПОСЛАТЬ СООБЩЕНИЕ (Пр2. Ml. ПЯ2):
ЖДАТЬ СООБЩЕНИЕ (ПрЗ. МЗ. ПЯ1);
Пр2:
ПОСЛАТЬ СООБЩЕНИЕ (ПрЗ. М2. ПЯЗ):
ЖДАТЬ СООБЩЕНИЕ (Пр1. Ml, ПЯ2);
ПрЗ:
ПОСЛАТЬ СООБЩЕНИЕ (Пр1. МЗ. ПЯ1):
ЖДАТЬ СООБЩЕНИЕ (Пр2. М2. ПЯЗ):
Примеры тупиковых ситуаций и причины их возникновения
251
Листинг 8.2. Вариант псевдокода с тупиковой ситуацией
Пр1:
ЖДАТЬ СООБЩЕНИЕ (ПрЗ. МЗ. ПЯ1):
ПОСЛАТЬ СООБЩЕНИЕ (Пр2, Ml. ПЯ2);
Пр2:
ЖДАТЬ СООБЩЕНИЕ (Пр1, Ml. ПЯ2);
ПОСЛАТЬ СООБЩЕНИЕ (ПрЗ. М2. ПЯЗ);
ПрЗ:
ЖДАТЬ СООБЩЕНИЕ (Пр2. М2. ПЯЗ);
ПОСЛАТЬ СООБЩЕНИЕ (Пр1. МЗ. ПЯ1):
В самом деле, во втором варианте ни один из процессов не сможет послать сообще-
ние до тех пор, пока сам его не получит, а это событие никогда не произойдет, по-
скольку ни один процесс не может этого сделать.
Пример тупика на ресурсах типа CR и SR
Пусть некоторый процесс Пр1 должен обменяться сообщениями с процессом Пр2
и каждый из них запрашивает некоторый ресурс R, причем Пр1 требует три едини-
цы этого ресурса для своей работы, а Пр2 — две единицы и только на время обра-
ботки сообщения. Всего же имеется только четыре единицы ресурса R. Запрос
и освобождение ресурса можно реализовать через соответствующий монитор с про-
цедурами REQUESTER, N) — запрос N единиц ресурса R, и RELEASE(R, N) —освобожде-
ние (возврат) N единиц ресурса R. Обмен сообщениями будем осуществлять через
почтовый ящик MB. Фрагменты программ Пр1 и Пр2 приведены в листинге 8.3.
Листинг 8.3. Пример тупика на ресурсах CR и SR
Пр1: REQUEST ( R, 3 ):
SEND_MESSAGE ( Пр2. сообщение, MB ):
WAIT_ANSWER ( ответ. MB );
RELEASE ( R. 3 );
WAIT_MESSAGE ( Пр1, сообщение. MB );
REQUEST ( R. 2 ):
ОБРАБОТКА СООБЩЕНИЯ:
RELEASE ( R, 2 ): продолжение ti>