Dubois E., Gray P., Nigay L. (Eds.) The Engineering of Mixed Reality Systems
Подождите немного. Документ загружается.


236 J. Williamson and R. Murray-Smith
Fig. 12.1 The MESH expansion pack, with an iPaq 5550 Pocket PC. This provides accelerometer,
gyroscope and magnetometer readings, as well as vibrotactile display
eccentric motor vibration unit, providing a lower frequency range of vibration sen-
sations than achievable with the VBW32, like a woofer would in an audio system,
at the cost of reduced temporal resolution. The accelerometers are used for sensing
and are sampled at 100 Hz, with a range of approximately ± 2 g. The gyroscopes
and magnetometers are not used. Capacitive sensing is used for tap detection (see
Section 12.5.2.2).
Earlier versions of the “Shoogle” system [22] also run on s tandard mobile phones
(such as the Nokia Series 60 devices), using the Bluetooth SHAKE inertial sen-
sor pack (see Fig. 12.2). This provides accelerometer measurement and vibrotactile
feedback in a matchbox-size wireless package, along with a range of other sens-
ing functionality (gyroscopes, magnetometers and capacitive sensing). Work is
underway in porting the automatic text message classification system to work trans-
parently with real SMS inboxes on mobile phones, so that the system can be tested
“in the wild”.
Fig. 12.2 The wireless SHAKE sensor, shown with a 2 Euro piece and a Nokia 6660 for size
comparison. This Bluetooth device comprises a complete inertial sensing platform with on-board
vibrotactile feedback
12 Multimodal Excitatory Interfaces 237
12.4 Object Dynamics
The behaviour of the interface is governed by the internal physical model which
defines the relation between sensed motions and the response of the component
objects whose i nteractions generate feedback events. Here, the simulated physical
system is based around objects bouncing around within a rectangular box whose
physical dimensions appear to be the same as the true physical dimensions of the
device. Each message in the inbox is mapped onto a single spherical object.
12.4.1 Accelerometer Mapping
The accelerations sensed by the accelerometers are used directly in an Euler inte-
gration model. This is quite sufficient given the relatively fast update rate and
the non-stiffness of the dynamics; the feedback properties also mean that small
numerical inaccuracies are imperceptible. The accelerations are high-pass filtered
to remove components under ∼ 0.5 Hz. This eliminates drifts due to changes in ori-
entation and avoids objects becoming “stuck” along an edge. These accelerations
are then transformed by an object-dependent rotation matrix (based on the message
sender, see Section 12.5.2.1) and a scaling matrix which biases the objects along a
specific axis:
¨x
i
= [a
x
a
y
a
z
]R
x
(θ
i
)R
y
(φ
i
)R
z
(ψ
i
)
⎡
⎣
1
α
0
⎤
⎦
, (12.1)
where a
x
, a
y
, a
z
are the readings from the acclerometer; θ
i
, φ
i
; and ψ
i
are the rotation
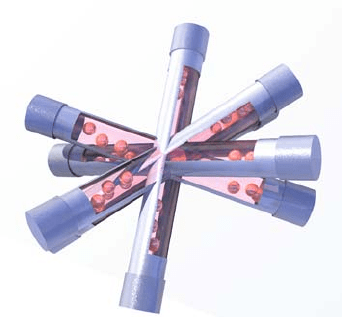
angles for object i; and 0 <α<1 is the direction-biasing term (see Fig. 12.3). As
α decreases, the region of the state space which will activate the object becomes
Fig. 12.3 The accelerations
are transformed before
application to the objects,
such that each object “class”
is excitable in a different
direction. The cylinders here
illustrate the different
directions along which the
device can be moved to excite
different classes (although
these are rather more oval
shaped in the simulation).
The cutaways show the
virtual objects (ball bearings)
within
238 J. Williamson and R. Murray-Smith
smaller. Any other projection of the acceleration vector could be used; this could
include more complex nonlinear projections. For example, the feature vector could
be extended to include a quadratic basis while still using a simple linear projection
matrix. The vector could also include estimated time derivatives of the acceleration
measurements.
12.4.2 Friction and Stiction
Nonlinear frictional damping is applied to the motion of the objects. This eliminates
rapid, small, irritating impacts caused by slight movements while remaining realistic
and sensitive. The friction function is a piecewise constant function, so that
f =
f
s
(|˙x| < v
c
)
f
m
(|˙x|≥v
c
)
, (12.2)
where f
s
and f
m
are the static and moving coefficients and v
c
is the crossover velocity.
These coefficients can be varied to simulate different lining materials within the box
or different object surfaces (e.g. smooth plastic versus velvet balls).
12.4.3 Springs
When objects are created, they are attached to a randomly allocated position within
the simulated box by a linear Hooke’s law spring, such that
¨x
q
= a
q
+
k(x
q
− x
q0
)
m
, (12.3)
where x
q0
is the anchor point (see Fig. 12.4). The spring coefficient k loosens or
tightens the motion of the balls. Without this spring motion, the system can feel
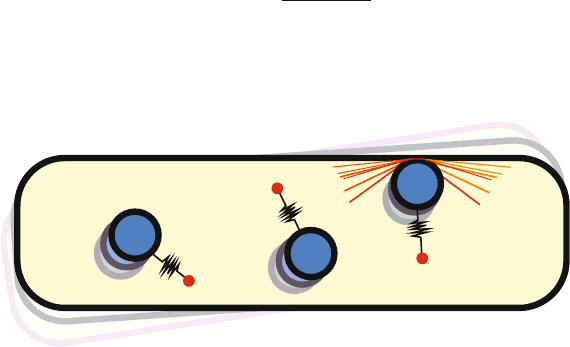
Fig. 12.4 The simulated system. A number of balls, anchored via springs, bounce around within
the virtual container. When they impact (as in the top right) sound and vibration are generated,
based on the physical properties of the impact and the properties of t he message with which they
are associated
12 Multimodal Excitatory Interfaces 239
unresponsive as objects tend to cluster together as a consequence of the constraints
created by walls. I t is only through the spring force that the mass of the balls enters
the dynamics calculations, although a more realistic system could include a mass
term in the friction computation.
12.4.4 Impacts
Feedback events are generated only when the balls collide with the walls of the
device “box”. These impacts trigger sample playback on both the vibrotactile and
audio devices. I nter-ball collisions are not tested for. Wall collisions are inelastic,
transferring some kinetic energy to the wall, and the remainder to rebound. The
rebound includes directional jitter – simulating a slightly rough surface – to reduce
repetitive bouncing.
12.5 Message Transformation
Each of these impacts is intended to communicate information about the message
with which it is associated. Due to the limitations of the haptic transducers, the
vibrotactile feedback varies in a very limited way; it largely serves as an indicator
of presence and gives an added degree of realism. The properties of each message
are instead sonified, modulating the impact sounds to reveal meta-data. This meta-
data is intended to summarize the contents of the inbox in a way which maintains
user privacy (other listeners will not obtain significant personal information) and
can be presented extremely rapidly.
Several transformations are used in the sonification process. The simplest trans-
formation involves linking the mass of each ball to the length of the SMS message.
Longer messages result in heavier balls with appropriate dynamics and suitably
adjusted resonances. The most important feature is association of impact “material”
to the output of a classifier which identifies language styles within the message. This
is similar in nature to the language model-based sonifications used in the speed-
dependent automatic zooming described in [3]. This aims to give an interacting user
some sense of the content or style of the messages rapidly, without visual display or
laborious text-to-speech output (which also has obvious privacy issues). The identity
of the message sender and relative time of arrival of the messages are also displayed,
by directional filtering and a rhythmic display, respectively. The impact sounds are
also panned according to the site of the impact; however, this is useful only when
the device is used with headphones.
12.5.1 PPM Language Model
The language modelling involves multiple partial-predictive-match (PPM) models
[1, 2]. These code text very well, approaching the theoretical maximum compression
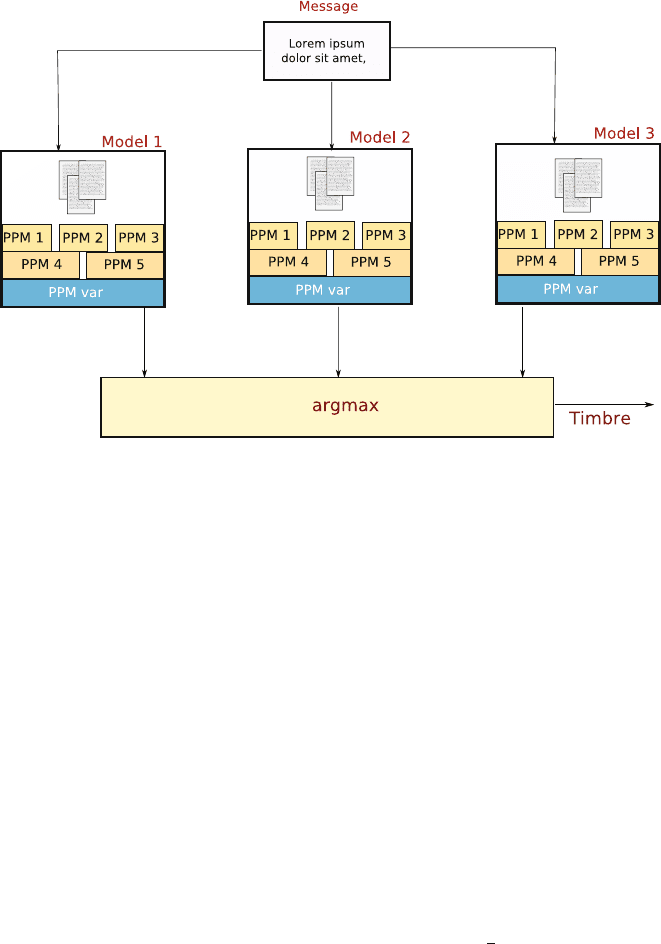
for English texts (see [17]). Figure 12.5 gives an overview of the process. Each class
240 J. Williamson and R. Murray-Smith
Fig. 12.5 The structure of the text classifier. Multiple models are run on incoming messages. Each
of these models is composed of a number of weighted submodels. The index of the classifier with
the highest posterior likelihood is used to select the i mpact timbre
of messages has a separate model θ
j
and is trained on a corpus of messages in that
style (e.g. in a particular language or in a specific vernacular).
The current implementation uses a hybrid structure, with one submodel trained
with variable length prefix, running from the start of the word and terminating at
the first non-letter character (which is particularly sensitive to keywords), combined
with a smoothed fixed-length PPM submodel. This provides a measure of robustness
in classification, especially where training t exts are sparse.
The smoothed submodel combines weighted PPM models of different length
(designated PPM
h
for a length h model, with PPM
0
being the model trained with
no prefix, i.e. t he independent distribution of characters), up to a length 5 model
p(c|r
f
) =
5
h=0
λ
h
p(c|PPM
h
), (12.4)
with the λ
0
...λ
5
,
5
h=0
λ
h
= 1 determining the weighting of the models. Symbols
unseen in the training text are assigned a fixed probability of
1
S
, where S is the total
number of possible symbols (e.g. all ASCII characters).
The fixed-length and word-length classifiers are used in a weighted combination,
such that under each model θ
j
, each character has a probability
p(c|θ
j
) = λ
q
p(c|r
v
) + (1 − λ
q
)p(c|r
f
), (12.5)
12 Multimodal Excitatory Interfaces 241
where λ
q
is a weighting parameter, r
v
is the variable length model and r
f
is the
smoothed fixed-length model.
This smoothing ensures that when the variable length model abruptly fails to pre-
dict subsequent characters (e.g. when a word not seen in the training text appears),
the system relaxes back to the fixed-length model, and the fixed-length model will,
in the worst case, revert to the independent distribution of characters in the training
text. For each model, a tree of probabilities are stored, giving p(c|r), where c is the
character predicted and r is the current prefix. The variable length model is pruned
during training so that nodes with observation count below a certain threshold are
cut off after a specified number of symbols have been seen. This reduces the size of
the tree sufficiently that it can be used without excessive memory consumption. A
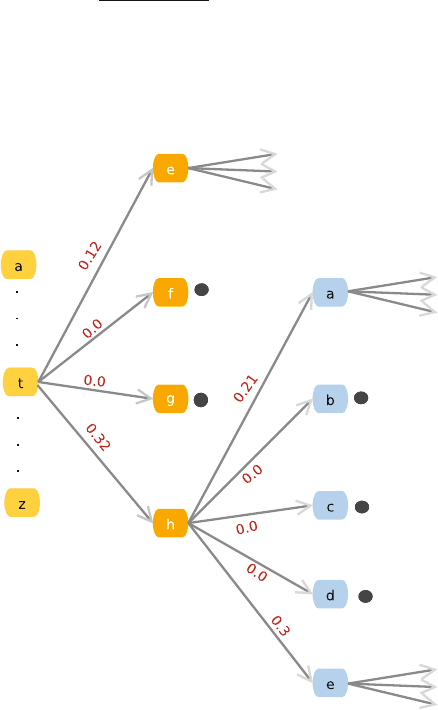
section of an example tree is given in Fig. 12.6.
The likelihood of a message is then just
p(θ
j
|text) =
p(text|θ
j
)p(θ
j
)
p(text)
. (12.6)
Assuming constant prior for all models, and under the assumption that any message
must belong to one of the initially trained classes, the model probabilities can be
Fig. 12.6 A sample language
model tree. The model is
stored as a graph, with the
edge weights being the
probabilities of each
transition, obtained from the
normalized counts of that
transition from t he training
corpus. Solid circles indicate
no further transitions from
this symbol. E ach submodel
has its own tree

242 J. Williamson and R. Murray-Smith
normalized such that
n
k=0
p(text|θ
k
) = 1, i.e. the posterior likelihood becomes
just
p(θ
j
|text) =
p(text|θ
j
)
n
k=0
p(text|θ
k
)
. (12.7)
For each model, we have
log p(text|θ
j
) =
END
i=0
log p(c
i
|θ
j
). (12.8)
Exponentiating and substituting (12.8) into (12.7), the model likelihoods are
obtained.
12.5.1.1 Potential Enhancements
Although word-level models of text could be introduced, these have significant
training requirements and require enormous storage for anything but the small-
est corpora. Given the excellent compression capabilities of the PPM models and
the good performance of the classifiers in the test scenarios (see Section 12.5.1.2),
additional modelling is probably excessive for the current problem.
Ideally, each of these classes would be adapted online, with the user assigning
incoming messages to particular classes, to cope with the various styles that user
regularly receives. Although this is not currently implemented, it would be relatively
simple to do so.
12.5.1.2 Test Model Classes
For testing, five language classes were created by selecting appropriate corpora. Due
to the lack of suitable t ext message corpora in different styles, a number of artificial
classes were created. Although these differences are exaggerated compared to the
types of messages commonly received, they demonstrate the utility of the technique.
Each of these was trained with a relatively small corpus, but this was sufficient given
the very significant differences in language. Table 12.1 shows the test classes and
their corresponding corpora.
Table 12.1 Test classes and the training texts used for them
Name Corpus Model
SMS SMS messages (Singapore corpus [10]) θ
1
Finnish Finnish poetry (Project Gutenberg) θ
2
News Collection of BBC News articles θ
3
German German literature (Project Gutenberg) θ
4
Biblical Old testament (KJV Genesis) θ
5

12 Multimodal Excitatory Interfaces 243
Table 12.2 Test results with the five classifiers. These short texts were taken from documents not present in the training corpus. Zeros are shown where the
probability is so close to 1 that the logarithm is not computed exactly. The entry with maximum probability for each row is highlighted in light grey. Theclass
codes are as follows: SMS (θ
1
); Finnish (θ
2
); News (θ
3
); German (θ
4
); Biblical (θ
5
)
Text True log
2
p(θ
1
)log
2
p(θ
2
)log
2
p(θ
3
)log
2
p(θ
4
)log
2
p(θ
5
) H(θ)
“yo what up wit u the night. u going to the
cinema?”
(θ
1
) −4.23 × 10
−5
−116.47 −18.98 −128.82 −15.15 4.9 × 10
−4
“Ken aina kaunis on, ei koskaan pöyhkä,
Nopea kieleltänsä, mut ei röyhkä; Ken rik
as on, mut kultiaan ei näytä; Tahtonsa
saada voi, mut sit ei käytä.”
(θ
2
) −233.32 0.0 −205.36 −186.36 −224.15 1.47 × 10
−54
“They are charged with crimes against
humanity over a campaign against Kurds
in the 1980s.”
(θ
3
) −80.08 −233.69 0.0 −253.54 −77.39 4.51 × 10
−22
“Die Erde ist nicht genug, Mond und
Mars offenbar auch nicht: Google will
demnächst das gesamte Universum
erfassen.”
(θ
4
) −185.69 −213.26 −159.05 0.0 −178.71 2.09 × 10
−46
“Now after the death of Joshua it came to
pass, that the children of Israel asked the
LORD, saying, Who shall go up for us
against the Canaanites first, to fight
against them.”
(θ
5
) −126.82 −438.91 −80.56 −484.06 0.0 4.99 × 10
−23

244 J. Williamson and R. Murray-Smith
Table 12.2 shows testing results from these classifiers. The table shows exam-
ple messages and their “true” class, along with the classifier probabilities and
the classifier entropy. The classifier performs extremely well, even for the less
well-distinguished categories.
12.5.1.3 Certainty Filtering
The timbre of the impact is always set to be the one associated with the most likely
model (see Section 12.6.2), but the output of the classifiers is clearly uncertain;
message classes can often be quite similar, and many messages may be either so
short or so generic as to be indiscriminable. The system displays this uncertainty by
manipulating the audio according to the entropy of the classifier distribution
H(θ|text) =−
n
j=0
p(θ
j
|text) log
2
p(θ
j
|text). (12.9)
The entropy sonification is performed in two ways: first, when H(θ|text) rises
above some threshold H
min
, the timbre associated with the message is set to be a
special class representing a “general message”; second, when the entropy is below
this threshold, a low-pass filter is applied to impact sound, with the cutoff inversely
proportional to the entropy
c =
z
ε + H(θ|text)
, (12.10)
for some constants z, ε. This dulls the sound as the entropy increases.
12.5.2 Exploration
The basic shaking system simply gives a sense of the numerosity and composi-
tion of the messages in the inbox. Two additional features extend the interaction to
present other aspects of message content. These rely on the device being stimulated
in different ways, rather than attempting to present more information in a single
impact.
12.5.2.1 Identity Sieving
Identity sieving links the sender or sender group (e.g. family, friends, work) of the
message (which can be obtained from the message meta-data) to a particular plane in
space (see Section 12.4). These messages can be excited by moving the device in this
plane; moving it in others will have less effect. A user can “sieve out” messages from
a particular sender by shaking in various directions. The stiction model increases the
selectivity of this sieving, so that objects who are free to move along other plains
tend not to do so unless more violent motions are made. All objects can still be
excited by making such vigorous movements.
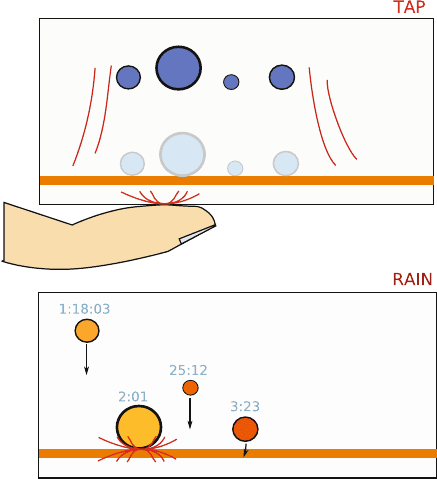
12 Multimodal Excitatory Interfaces 245
Fig. 12.7 Capacitive sensors
detect tap motions on the case
of the device. This causes the
virtual objects to be launched
up and then rain back down
so that the timing of the
impacts reveals the relative
timing of the arrival of the
associated messages. Here,
the times shown in light blue
are arrival times (the time
since this message arrived),
so that the newest message
impacts first
12.5.2.2 Time-Sequenced “Rain”
An additional overview of the contents of the inbox can be obtained by tapping the
device, causing the balls to shoot “upwards” (out of the screen) and then fall back
down in a structured manner. Tapping is sensed independently using the capacitive
sensors on the MESH device and is reliable even for gentle touches while being
limited to a small sensitive area. The falling of the objects is linked to the arrival
time of the messages in the inbox, with delays before impact proportional to the
time gap between the arrival of messages. The rhythm of the sounds communicates
the temporal structure of the inbox. Figure 12.7 illustrates this.
12.6 Auditory and Vibrotactile Display
The presentation of timely haptic responses greatly improves the sensation of a
true object bouncing around within the device over an audio-only display. As
Kuchenbecker et al. [12] describe, event-based playback of high-frequency wave-
forms can greatly enhance the sensation of stiffness in force-feedback applications.
In mobile scenarios, where kinaesthetic feedback is impractical, event-triggered
vibration patterns can produce realistic impressions of contacts when the masses
involved are sufficiently small.