Андон Ф.И., Коваль Г.И., Коротун Т.М., Лаврищева Е.М., Суслов В.Ю. Основы инженерии качества программных систем
Подождите немного. Документ загружается.

234 Глава 5
• несколько точек находятся вблизи контрольных пределов.
Нужно отметить, что кроме X- и R-карт, существуют и другие полезные виды
контрольных карт, используемые в инженерии качества ПС (например, XmR, U, Z,
S и другие карты) [48].
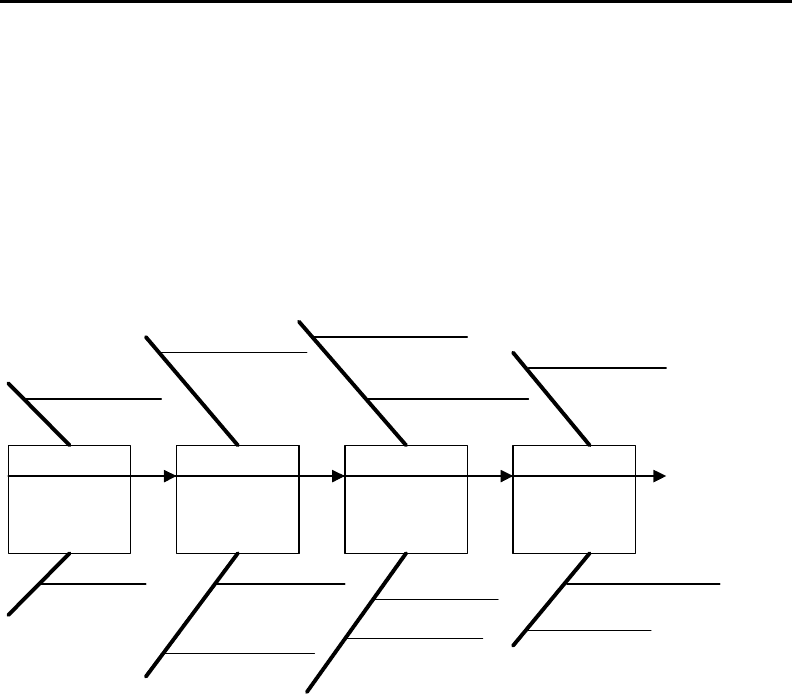
Причинно-следственная диаграмма. Причинно-следственная диаграмма
(C&E, Cause and Effect diagram) используется для того, чтобы установить множест-
во возможных причин появления одной изучаемой проблемы. Другие названия это-
го графического инструмента - диаграмма Исикавы, «рыбья кость» (fish-bone),
диаграмма анализа первопричин (root cause analysis). Наиболее эффективно приме-
няется в условиях коллективной работы над проблемой в режиме мозгового штур-
ма. Пример диаграммы показан на рисунке 5.23.
отчеты о проблеме
регистрируются
своевременно не
нельзя локализовать
артефакты ПС,
связанные с
проблемой
контроль изменений
выполняется только
раз в неделю
решения об изменениях
своевременно не
выполняются
задержки в проверке
внесенных
изменений
очень долго
отрабатываются
запросы об
изменениях
программной
системы
Категория 1 Категория 2
Категория 3 Категория 4
Сбор отчетов о
проблемах
Оценка
возможности
внести
изменения
Внесение
изменений
Закрытие
проблемы
в отчете
отсутствует
нужная информация
нельзя определить
как локализовать
проблему
нельзя воспроизвести
ситуацию
большие затраты
времени на
переделки
нужно
реконфигурировать
базовую версию
задержки в отправке
релизов
задержки в пути
Рис. 5.23. Пример C&E диаграммы для процесса сопровождения системы
Основная линия диаграммы (хребет рыбы) отображает проблему (или харак-
теристику, которую нужно улучшить или проконтролировать) и имеет обозначение
на правом конце. Ответвления от основной линии (главные кости, отходящие от
хребта) диаграммы размещаются под углом к ней и соответствуют главным причи-
нам (или категориям причин), непосредственно связанным с проблемой (для на-
глядности категории указаны в блоках на основной линии диаграммы). Обычно
выделяют 3 – 6 категорий причин. Далее каждое ответвление вновь интерпретиру-
ется как основная линия – представитель проблемы более низкого, второго уровня
рассмотрения, и уже относительно этой линии производится ветвление причин.
Практически полезная глубина ветвления – 4-5 уровней проблем. Таким образом,
C&E диаграмма используется для представления всех обнаруживаемых потенци-
альных или реальных причин, детализируемых и упорядочиваемых по уровням
важности. Она помогает установить первопричины существующей или возможной
проблемы, идентифицировать области риска и ранжировать риски по степени отно-
сительной важности.
C&E диаграмма может также изображаться в виде лежащего дерева (рисунок
5.24).
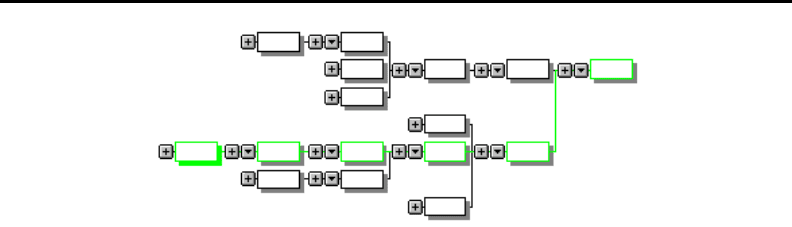
Глава 5 235
Рис. 5.24. Пример древовидного изображения диаграммы C&E на компьютере
Изображение в виде дерева имеет преимущества перед «скелетом рыбы», по-
скольку с ростом сложности диаграммы становится все сложнее находить и срав-
нивать разбросанные по диаграмме «равновеликие» причины, вносящие одинако-
вый вклад в исследуемую проблему. При древовидной структуре все элементы диа-
граммы, находящиеся на одном и том же каузальном уровне, выравниваются по
вертикали.
Существует множество других графических средств, применяемых для пред-
ставления и анализа информации о процессах и программных продуктах. Они хо-
рошо известны и не нуждаются в описании. В их числе:
• диаграмма «сущность-связь» (entity-relations diagram),
• диаграмма потоков управления и данных (flow chart),
• контрольный листок (сheck sheet) (пример приведен в главе 4),
• матричная диаграмма (пример – совокупность матриц в методологии
QFD),
• вопросник (checklist).
5.3.2. Применение методов интеллектуального анализа данных
Конец XX века отметился появлением и бурным развитием технологии ин-
теллектуального анализа данных (ИАД) или добычи данных (DM, Data Mining),
обусловленным необходимостью аналитической обработки сверхбольших объемов
информации, накапливаемой в современных хранилищах данных [49], [50]. Эле-
менты этой технологии находят применение и в инженерии качества ПС [51].
Процесс добычи данных в инженерии качества заключается в извлечении ра-
нее неизвестной и потенциально полезной информации из множества разрозненных
(сырых) исторических данных измерений с целью выявления скрытых закономер-
ностей и принятия обоснованных решений относительно контроля качества про-
граммных продуктов и процесса разработки.
Особенность анализируемых данных состоит в том, что они могут представ-
лять результаты измерений, выполненных в различных организациях с применени-
ем разных метрик (отвечающих целям этих организаций) и структурированных та-
ким образом, что к ним сложно непосредственно применить автоматизированные
или полу автоматизированные методы извлечения знаний без предварительной об-
работки. Суррогатные наборы данных могут содержать лишние или несуществен-
ные данные (шумы), массивы с пропущенными данными и др. Поэтому перед при-
менением к ним алгоритмов DM данные из различных источников должны быть
просеяны, интегрированы и согласованы.
Процесса добычи данных включает 4 шага:

236 Глава 5
Шаг 1. Выбор типов данных, для которых будет применяться алгоритм из-
влечения знаний, идентификация расположения данных, получение к ним доступа
и транспортировка в одно централизованное хранилище – репозиторий - для после-
дующего применения.
Шаг 2. Предварительная обработка данных, которая заключается в просеива-
нии данных, форматировании, преобразовании типов, нормализации, выявлении
неопределенных или отсутствующих значений, а также, «порождении» новых ат-
рибутов (как, например, атрибут «серьезность дефекта», который может быть по-
рожден для сущности «дефект» как функция от «времени обнаружения», «времени
локализации» и «времени устранения» дефекта).
Шаг 3. Применение алгоритма добычи данных – извлечение интересной и
потенциально полезной информации путем применения моделей и методов выяв-
ления знаний. Предварительно обработанные данные могут использоваться, на-
пример, для:
1.
разработки точной классификационной модели предсказания количества
дефектов в программных модулях (сама модель будет представлять собой новую
информацию);
2.
автоматического построения диаграмм, отражающих интересные ассо-
циации между характеристиками проекта и профилями ошибок (новая информация
будет получена в результате последующего исследования диаграмм);
3.
получения целостной картины проективных характеристик и профилей
ошибок с помощью инструментов визуализации данных (новая информация будет
извлечена в результате интерактивного исследования визуальных образов данных).
Эти примеры представляют основные направления добычи данных – по-
строение моделей, автоматическое исследование образцов (pattern extraction) и ви-
зуальное исследование данных (visual data exploration).
Шаг 4. Интерпретация (ассимиляция) извлеченной информации – оценивание
надежности и эффективности разработанных моделей или определение экспертом в
данной проблемной области степени новизны и полезности новой информации.
В поиске интересной информации шаги процесса добычи данных могут по-
вторяться неоднократно – аналитик может изменить критерий выбора данных, если
посчитает информацию неинтересной; произвести дальнейшую фильтрацию дан-
ных, если они не адекватны алгоритму DM; уточнить алгоритм, если в результате
его применения обнаруживается слишком мало интересных фактов.
Качество извлеченной информации зависит как от правдивости исходных
«сырых» данных, так и от методов, используемых в процессе добычи данных, а
также способностей аналитиков правильно выполнять действия по DM.
Выбор методов добычи данных определяется задачами, которые должны ре-
шаться с использованием анализа исторических данных в области программной
инженерии. Основные задачи классифицируются по следующим категориям:
Задачи оценивания и прогнозирования. Исследование атрибутов множества
сущностей (продуктов, процессов и ресурсов) и использование их значений для
квантификации нового исследуемого атрибута. Например, прогнозирование трудо-
емкости разработки ПС по известным характеристикам проекта. Для решения этих
задач могут использоваться такие методы DM, как нейронные сети (artificial neural
network) [52] или байесовские сети (Bayesian belief network) [53], которые позво-

Глава 5 237
ляют строить достоверные прогнозы, не уточняя конкретный вид тех зависимостей,
на которых прогноз основан. Подробнее о байесовских сетях – в п.5.3.3.
Задачи классификации. Исследование атрибутов заданной сущности и отне-
сение ее к определенному классу или категории, основываясь на значениях этих
атрибутов. Например, отнесение модулей к одному из двух классов – «с большой
вероятностью дефектов» или «с малой вероятностью дефектов». Для решения этих
задач могут использоваться методы деревьев классификации (classification trees)
[54] или оптимального сокращения набора данных (optimal set reduction) [55] (это
метод иерархической классификации).
Задачи выявления ассоциаций. Поиск ассоциативных групп значений атри-
бутов, т.е. значений, почти всегда появляющихся вместе. Например, определение
того, какие значения двух атрибутов - «опыт» и «подготовка» - для сущности
«группа разработки» ассоциируются с характеристикой качества конечного про-
дукта - «надежность». Для решения этих задач может использоваться метод анали-
за взаимосвязанных событий (анализа структуры транзакции) (в экономике этот
метод называют методом анализа структуры покупки (market basket analysis)) [56]
или метод анализа значений атрибута (attribute focusing) [57]. По первому методу
анализируются «интересные» события и связанные с ними значения атрибутов, а по
второму - «интересная» функция распределения значений или «интересные» корре-
ляции между значениями атрибутов. Установленные факты отображаются с помо-
щью столбиковых диаграмм, упорядочиваемых по степени «интереса», который
они представляют для экспертов. Вопросы, которые возникают у экспертов в про-
цессе анализа диаграмм, и побуждают к извлечению новых знаний.
Задачи кластеризации. Отличаются от задач классификации тем, что классы
или категории, к которым должны быть отнесены сущности, заранее не заданы и
должны быть сформированы в результате определения множества однородных
подгрупп данных. Разделение популяции данных на подгруппы производится не в
соответствии с какой-либо моделью классификации, а по измерениям расстояния
между ними. Если, например, база данных содержит записи о модулях системы и
нужно разделить все множество записей на группы, руководствуясь значениями
атрибута «количество модификаций», расстояние будет измеряться разницей меж-
ду количеством модификаций разных модулей. Это простейший вид кластеризации
по одному критерию. Обзор методов и алгоритмов иерархической и неиерархиче-
ской кластеризации данных можно найти, например, в работах [58] и [59].
Задачи визуализации данных. Визуализация данных заключается в отобра-
жении многомерных данных на двумерном экране компьютера. Достигается путем
связывания записей данных с «визуальными атрибутами», каждый из которых да-
лее ассоциируется с измерением реальных данных. Хороший пример использова-
ния приемов визуализации в программной инженерии - работы Data Visualization
Research Group (AT&T Bell Labs) по визуализации исходного кода программ [60].
Задачи исследования визуализированных данных. Осмысление сложной
информации с помощью интерактивного управления визуализацией многомерных
неструктурированных наборов данных путем построения сценариев отображения
данных в режиме «что если». Обзор современных инструментов визуальной добы-
чи данных, позволяющих эксперту в проблемной области обнаруживать интерес-
ные образы данных без использования автоматизированных алгоритмов, представ-
лен в [51].
238 Глава 5
5.3.3. Графические инструменты для построения байесовских сетей
Существует множество инструментальных средств для построения графиче-
ских моделей, основанных на байесовских сетях [61, 62].
В таблице 5.13 представлены результаты анализа возможностей некоторых
доступных в Интернет инструментов построения байесовских сетей, функциони-
рующих под управлением Windows. В графе “Адреса” указаны ссылки на адреса
сайтов в Интернет, на которых обеспечен доступ к инструментам.
Инструменты сравнивались по критериям:
- поддержка разных типов случайных величин в вершинах (Н – непре-
рывные (с Гауссовским распределением), Д – дискретные);
- наличие API-интерфейса для встраивания функций сети в программные
приложения на Visual Basic и VBA;
- ограничение функциональных возможностей доступной версии.
Таблица 5.13. Сравнение инструментов построения байесовских сетей
Назва-
ние
Ад-
рес
Тип
СВ
API Ограничение
MSBNx [63] Д Да Полная версия. Без ограничений. Не коммерческий
Netica [64] Д/Н Да Нет API в demo-версии. Коммерческий
Serene [65] Д/Н Нет Serene 1.0 Demo (до 40 вершин). Не коммерческий
Hugin [66] Д/Н Да Версия Hugin Lite 6.5 (до 50 вершин, до 500 комбинаций
значений СВ). Коммерческий
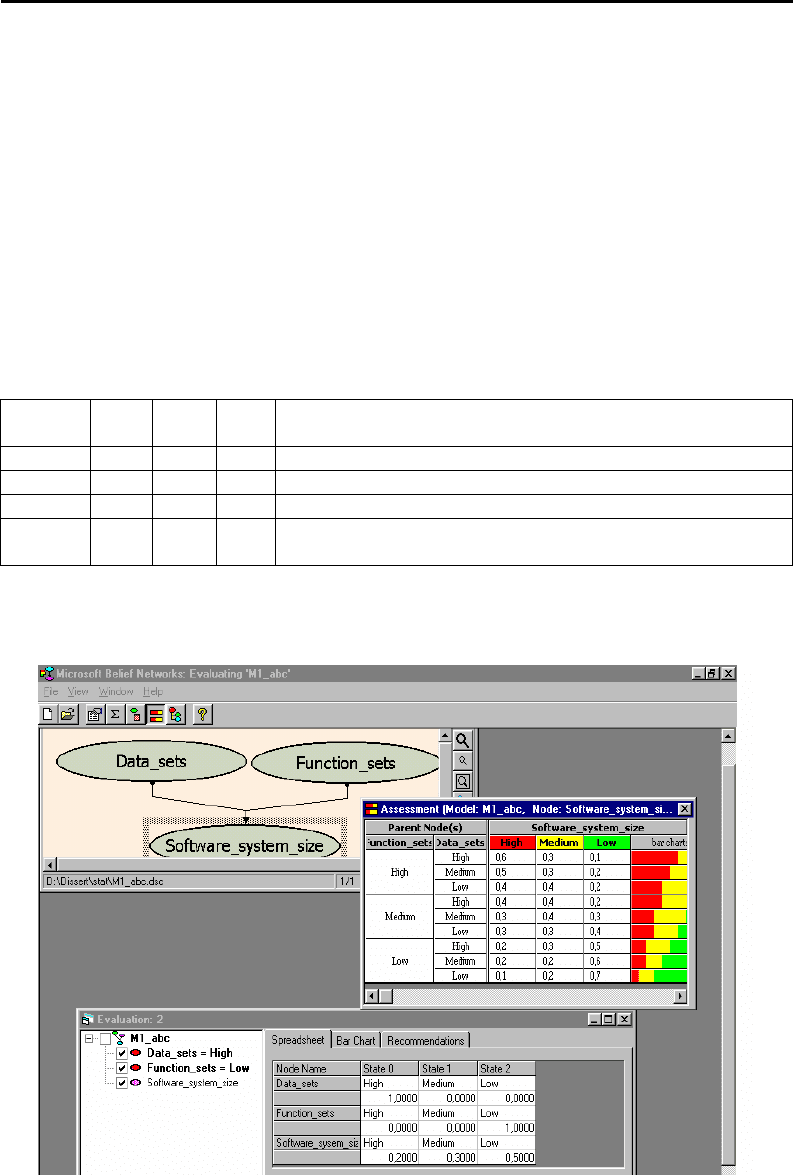
На рисунке 5.25 показан пример использования MSBNx для построения бай-
есовской сети с дискретными случайными величинами в вершинах, представленной
ранее в главе 3 (в п.3.2.6, рисунок 3.9).
Рисунок 5.25. Пример сети, построенной с помощью MSBNx
Глава 5 239
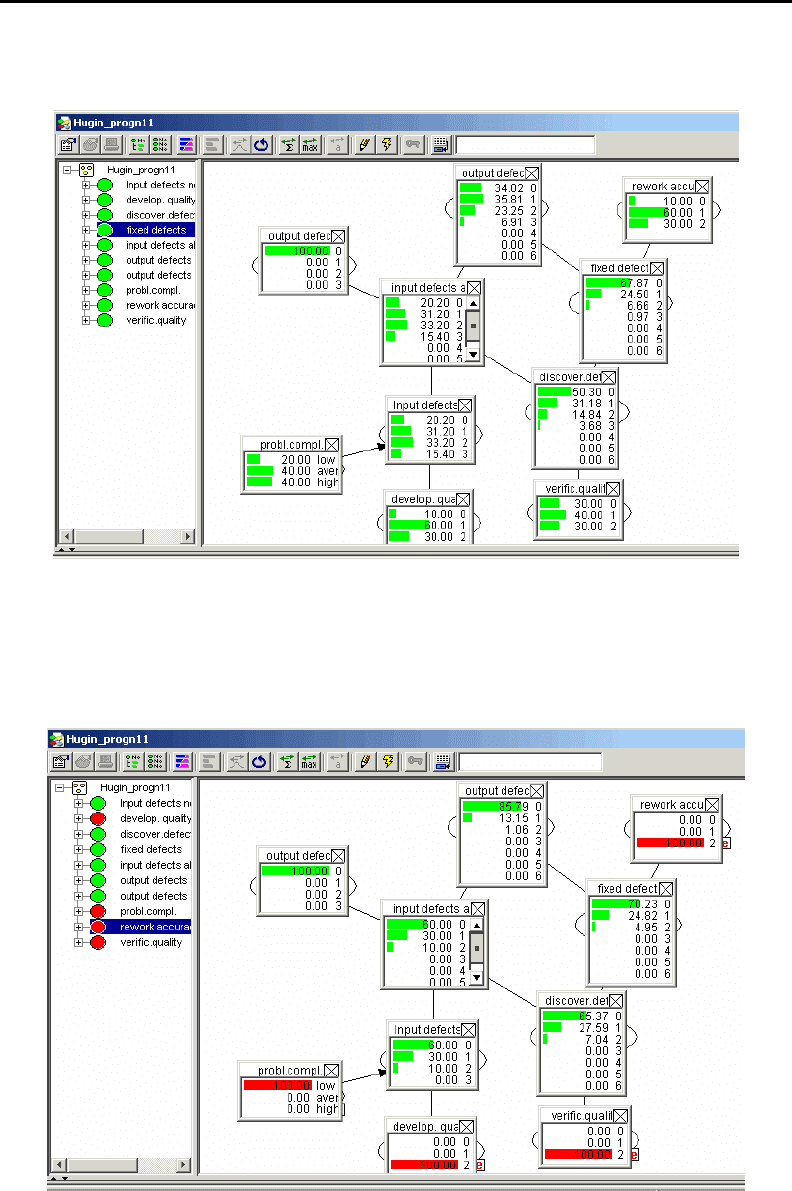
На рисунке 5.26 показана инициализированная байесовская сеть для прогно-
зирования дефектов, представленная в главе 3 (п.3.2.6, рисунок 3.11). Сеть по-
строена с помощью инструмента Hugin Lite 6.5.
Рис. 5.26. Априорные распределения вероятности в байесовской сети
Правильность и чувствительность построенных байесовских моделей прове-
ряется на оптимистическом и пессимистическом гипотетическом сценариях.
Для примера на рисунке 5.27 показан оптимистический сценарий событий
при разработке программного приложения, моделируемый той же байесовской се-
тью для прогнозирования дефектов (см. рис. 3.11).
Рис. 5.27. Оптимистичный сценарий событий в проекте

240 Глава 5
Если при разработке приложения сложность проблемы квалифицируется как
низкая, а качество разработки (вероятность предотвратить дефекты) и проверки
(вероятность найти дефекты) высокие, а также высокая точность устранения де-
фектов (вероятность правильно откорректировать код), - плотность дефектов будет
очень низкой (с вероятностью 86%).
5.3.4. Поддержка качества в CASE-инструментах
Современные CASE-инструменты автоматизируют большую часть периоди-
чески повторяющейся ручной работы разработчиков программных систем и при
правильном использовании повышают производительность труда проектировщиков
и программистов на всех стадиях ЖЦ ПС. В их состав входит множество компо-
нентов (оконечных инструментов) и утилит, поддерживающих решение традици-
онных задач разработки ПС - описания деловых процессов в проблемной области,
эскизного, технического, рабочего проектирования и макетирования программного
и информационного обеспечения ПС.
Однако возможности CASE-инструментов далеко не ограничиваются под-
держкой основных процессов ЖЦ. Они содержат средства, которые могут приме-
няться при выполнении поддерживающих процессов ЖЦ и способствовать повы-
шению качества ПС. Краткая характеристика некоторых интегрированных CASE-
инструментов дана в приложении 4.
Литература к главе 5
1. IEEE Std. 730:1998. IEEE Standard for Software Quality Assurance Plans.
2. NASA Std. 2201:1993. Software assurance standard.
3. MIL Std. 498:1994. Software Development and Documentation.
4. ISO/IEC 12207:1995. Information Technologies – Software life cycle processes.
5. NASA GB A201:1995. Software assurance guidebook.
6. IEEE Std. 730-1:1995. IEEE Guide for Software Quality Assurance Planning.
7. Мороз Г.Б., Коваль Г.И., Коротун Т.М. Концепция профилей в инженерии надежности
программных систем // Математические машины и системы. – 2004. – С. 166 – 182.
8. Липаев В.В. Обеспечение качества программных средств. Методы и стандарты. Серия
«Информационные технологии». М.: СИНТЕГ, 2001. – 380 с.
9. Бабенко Л.П., Лавріщева К.М. Основи програмної інженерії: Навчальний посібник. –
К.: Знання, 2001. – 269 с.
10. Вендров А.М. CASE – технологии. Современные методы и средства проектирования
информационных систем. М.: Финансы и статистика, 1998.
11. Липаев В.В. Тестирование программ - М.: Радио и связь, 1986. – 296 с.
12. Липаев В.В. Отладка сложных программ – М.: Энергоатомиздат, 1993. - 296 с.
13. Шураков В.В. Надежность программного обеспечения систем обработки данных: Учеб-
ник. – М.: Финансы и статистика, 1987. – 272 с.
14. Липаев В.В. Выбор и оценивание характеристик качества программных средств. Мето-
ды и стандарты. Серия «Информационные технологии». М.: СИНТЕГ, 2001. – 228 с.
15. Липаев В.В. Качество программных средств. - М.: «Янус-К», 2002. – 400 с.
16. Орлик С., Булуй Ю. Программная инженерия и управление жизненным циклом. -
http://software-testing.ru/lib/se/

Глава 5 241
17. Основы инженерии качества программных систем / Ф.И. Андон, Г.И. Коваль, Т.М. Ко-
ротун, В.Ю. Суслов – К.: Академпериодика, 2002. – 504 с.
18. Кулаков А.Ф. Оценка качества программ ЭВМ. – К.: Техніка, 1984. – 167 с.
19. Майерс Г. Надежность программного обеспечения. – М.: Мир, 1980. – 360 с.
20. Гласс Р. Руководство по надежному программированию. – М.: Финансы и статистика,
1982. – 256 с.
21. Липаев В.В. Надежность программных средств. – М.: СИНТЕГ, 1998. – 231 с.
22. Карповский Е.Я., Чижов С.А. Надежность программной продукции.–К.:Техніка., 1990
23. Боэм Б.У. Инженерное проектирование программного обеспечения. – М.: Радио и связь,
1985. – 511 с.
24. Тейер Т., Липов М., Нельсон Э. Надежность программного обеспечения. – М.: Мир,
1981. – 325 с.
25. Humphrey W.S. The Personal Software Process // Technical Report CMU/SEI-2000-TR-022.
– Software Eng. Inst., Pittsburgh, PA 15213-3890, 2000. - 55 p.
26. Humphrey W.S. The Personal Software Process: Status and Trends // IEEE Software,
nov./dec. 2000. – P. 71 - 75.
27. Ferguson P. et al. Results of Applying the Personal Software process // IEEE Conputer, may
1997. – P. 24 – 31.
28. Humphrey W.S. The Team Software Process // Technical Report CMU/SEI-2000-TR-023. –
Software Eng. Inst., Pittsburgh, PA 5213-3890, 2000. - 51 p.
29. Curtis B., Hefley W.E., Miller S.A. People Capability Maturity Model. Version 2.0 Technical
Report CMU/SEI-2001-MM-01. -Software Eng. Inst., Pittsburgh, PA 5213-3890, 2000.–735p.
30. ISO/IEC 15504-5:2006. Information Technologies - Process assessment - Part 5: An exemplar
Process Assessment Model
31. DEF STAN 0055:1997. Requirements for Safety Related Software in Defence Equipment
32. Albrecht A., Gaffney J. Software Function, Source Lines of Code and Development Effort
Prediction: A Software Science Validation // IEEE Trans. S. E.- 1983.- V.9.- N.11.-p.639-648.
33. Fenton N. A Critique of Software Defect Prediction Models // IEEE Trans. Soft. Eng.- 1999.-
V.25.-N.5.-p.675-689
34. Холстед М.Х Начала науки о программах. – М.: Финансы и статистика, 1988. – 128 с.
35. Watson A.H., McCabe T.J. Structured Testing: A Testing Methodology Using the Cyclomatic
Complexity Metric // NIST Spec. Publ. 500-235, NIST, Gaithersburg.- 1996. – 124 p.
36. Fenton N., Neil M. Software metrics: successes, failures and new directions // J. Systems
Software.- v.47, n.2-3.- 1999. - p. 149-157.
37. Applying and interpreting object oriented metrics - http://satc.gsfc.nasa.gov/support/
STC_APR98/apply_oo/apply_oo.html.
38. Voas J., Morell L., Miller K. Predicting where faults can hide from testing // IEEE Software.-
1991.-March.- p.41-48.
39. Коваль Г.И. Подход к прогнозированию надежности ПО при управлении проектом //
Проблемы программирования. –2002. - № 1 – 2. – С. 282 – 290.
40. Kan S.H. Metrics and models in software quality engineering // Addison-Wesley, 1995.
41. ISO./IEC 15939 Software engineering – Software Measurement Process.
42. International Vocabulary of Basic and General Terms in Metrology (VIM). - ISO. -1993.
43. W. Suryn, A.Abran, A.April ISO/IEC SQuaRE. The second generation of standards for soft-
ware product quality // www.lrgl.uqam.ca/publications/pdf-presentations/ 799.pdf

242 Глава 5
44. http: //www.info.fundp.ac.be/~nha/Monsite/PubsPdf/Rek(Square)2005.pdf
45. ISO/IEC PDTR 25021 Software and System Engineering - Software Product Quality Re-
quirements and Evaluation (SQuaRE) – Measurement Primitives. - ISO/IEC JTC1/SC7 WG6,
September 30, 2004, 6/N-521.
46. Исикава К. Японские методы управления качеством. – М.: Экономика, 1988. – 216 с.
47. Электронный учебник по промышленной статистике.- М., StatSoft, Inc. – 2001.
(www.statsoft.ru/home/portal/textbook_ind/default.htm)
48. Florac W.A., Park R.E., Carleton A.D. Practical Software Measurement: Measuring for Proc-
ess Management and Improvement //CMU/SEI-97-HB-003.-Pittsburgh, 1997.–246p.
49. Шапот М. Интеллектуальный анализ данных в системах поддержки принятия решений
// Открытые системы. - http://atlant.osp.ru/os/1998/01
50. Буров К. Обнаружение знаний в хранилищах данных // Открытые системы. -
http://atlant.osp.ru/os/1999/05-06
51. Mendonca M., Sunderhaft N.L. Mining Software Engineering Data: A Survey //
www.dacs.dtic.mil/techs/datamining/datamining.pdf
52. Khoshgoftaar T.M., Pandya A.S., Lanning D.L. Application of neural networks for predicting
faults // Annals of Software Engineering. – n.1. – 1995. – P. 141 - 154.
53. Fenton N., Neil M. Making Decisions: Using Bayesian Nets and MCDA // Knowledge-Based
Systems. – n.14. – 2001. – P. 307 - 325.
54. Porter A.A., Selby R.W. Empirically Guided Software Development Using Metric-Based
Classification Trees // IEEE Software. – v.7. – n.2. - March 1990. - P. 46 - 54.
55. Briand L.C., Basili V.R., Hetmanski C.J. Developing Interpretable Models with Optimized
Set Reduction for Identifying High-Risk Software Components //IEEE Trans.on Soft.Eng.. –
v.19. – n.11. – 1993. - P.1028 - 1044.
56. Hu Z., Chin W.N., Takeichi M. Calculating a New Data Mining Algorithm for Market Basket
Analysis // Second Intern. Workshop on Practical Aspects of Declarative Languages
(PADL'00), Boston, Massachusetts, Jan. 17-18, Springer Verlag.- 2000.- P. 169 -184.
57. Colet E., Bhandari I. S. Statistical Issues in the Application of Data Mining to the NBA Using
Attribute Focusing // Proc. of the Section on Statistics in Sports of the 1997 Joint Statistical
Meetings, Anaheim, CA, American Statistical Association. - 1997. – P. 1-6.
58. Jain K., Murty M. N., Flynn P. J. Data clustering: a review // ACM Computing Surveys. –
1999.- V.31. N. 3. - P. 264-323.
59. Ng R.T., Han J. Efficient and Effective Clustering Methods for Spatial Data Mining // VLDB.
– 1994. – P. 144-155.
60. Information Visualization Resources // www.cs.man.ac.uk/~ngg/InfoViz/People/ Publications/
61. Heckerman D., Mamdani A., Wellman M. Real-world applications of Bayesian networks //
Comm. ACM. – 1995. - № 3. – С. 25-26.
62. Murphy K.P. Brief Introduction to Graphical Models and Bayesian Networks. http://
HTTP.CS.Berkeley.EDU/~murphyk/Bayes/bayes.html.
63. MSBNx. Продукт Microsoft Research corp. // research.microsoft.com/ adapt/MSBNx/
64. Netica. Продукт Norsys Software corp.// www.norsys.com/download.html
65. Serene. ESPRIT Framework IV Collaborative Project 22187 //www.dcs.qmul.ac.uk/
~norman/serene.htm
66. Hugin Lite 6.5. Продукт Hugin Expert //www.hugin.com/roducts_Services/ ro-
ducts/Demo/Download/

243
Глава 6. ПРОЦЕССЫ И МЕТОДЫ ПРОВЕРКИ
6.1. Процессы проверки в жизненном цикле
6.1.1. Назначение процессов проверки
Наряду с процессом обеспечения гарантии качества, в архитектуре процессов
ЖЦ определены еще четыре процесса поддержки, всецело направленных на повы-
шение качества ПС. Это процессы Верификации, Валидации, Совместного про-
смотра и Аудита
1
, которые предназначены для проверки соответствия рабочих
продуктов и процессов разработки своему назначению и подтверждения их способ-
ности обеспечить надлежащее качество конечного программного продукта.
Исходя из положений стандарта ISO/IEC 12207 [1] «назначение процесса ве-
рификации состоит в подтверждении того, что каждый рабочий продукт ПС (soft-
ware work product) и/или услуга процесса или проекта должным образом отражают
установленные требования. В результате успешного осуществления процесса:
• будет разработана и внедрена стратегия верификации;
• будут установлены критерии верификации всех необходимых рабочих
продуктов ПС;
• будут выполняться надлежащие действия по верификации;
• будет выполняться поиск дефектов в рабочих продуктах и их устранение;
• будет обеспечиваться доступ заказчика и других заинтересованных сторон
к результатам верификационной деятельности…
Назначение процесса валидации состоит в подтверждении того, что требо-
вания, касающиеся конкретного применения рабочего продукта ПС по назначе-
нию, удовлетворяются. В результате успешного осуществления процесса:
• будет разработана и внедрена стратегия валидации;
• будут идентифицированы критерии валидации для всех нужных рабочих
продуктов;
• будет проводиться надлежащая валидационная деятельность;
• будут решаться все обнаруженные проблемы;
• будут предоставляться свидетельства того, что разработанные рабочие
продукты ПС отвечают своему назначению;
• будет обеспечиваться доступность результатов валидационной деятель-
ности для заказчика и других заинтересованных сторон».
Анализируя определения стандарта достаточно сложно установить грань ме-
жду процессами верификации и валидации, поскольку оба процесса применимы к
«рабочим продуктам ПС» (software work product). В действующем стандарте
ISO/IEC 12207 (1995 года) эта грань проведена четче: понятие верификации связы-
вается с программными продуктами (software products) деятельности по разработке
ПС, а валидации – с «конечным программным продуктом» (final software product).
1
Наименование группы и отдельных процессов ЖЦ соответствуют ДСТУ 3918-99. В
аналогичном стандарте России ГОСТ Р ИСО/МЭК 12207 группа процессов поддержки на-
звана группой вспомогательных процессов, процесс валидации - процессом аттестации, а
процесс совместного просмотра - процессом совместного анализа, что не меняет сути этих
процессов.