Захаров С.С. Учебное пособие по дисциплине Компьютерная графика
Подождите немного. Документ загружается.

здесь интерполируется не значение интенсивности по уже известным ее значениям в
опорных точках, а значение вектора внешней нормали, которое затем используется для
вычисления интенсивности пикселя. Поэтому закраска Фонга требует заметно большего
объема вычислений. Правда, при этом и изображение получается более близким к
реалистичному (в частности, при закраске Фонга зеркальные блики выглядят довольно
правдоподобно).
Метод Фонга заключается в построении для каждой точки вектора, играющего
роль вектора внешней нормали, и использовании этого вектора для вычисления
освещенности в рассматриваемой точке по формуле (5). При этом схема интерполяции,
используемая при закраске Фонга, аналогична интерполяции в закраске Гуро.
Для определения вектора «нормали»
W
n
в точке W проводим через эту точку
горизонтальную прямую и, используя значения векторов «нормалей»
U
n
и
V
n
в точках
ее пересечения U и V с ребрами грани, получаем
VU
VU
w
tnnt
tnnt
n
)1(
)1(
, где
UV
UW
t
,
а векторы внешних нормалей в точках U и V находятся, в свою очередь (также линейной
интерполяцией), по векторам нормалей в концевых точках соответствующих ребер
рассматриваемой многоугольной грани:
14
)1(
VVU
unnun
,
21
)1(
VVV
vnnvn
, где
14
4
VV
UV
u
,
21
1
VV
VV
v
.
Нормирование вектора
W
n
необходимо вследствие того, что в формулах (1)-(5)
используется единичный вектор нормали.
Как и метод Гуро метод Фонга также в значительной степени носит
инкрементальный характер.
Применяя метод Фонга, мы фактически строим на многогранной модели
непрерывное поле единичных векторов, использование которого в качестве поля внешних
нормалей обеспечивает гладкость получаемого изображения.
Ясно, что требования к качеству изображения напрямую связаны с точностью
рассматриваемой модели и объемом соответствующих ей вычислений. Несомненным
достоинством предложенных моделей закраски (Гуро и Фонга) является их сравнительная
простота. Однако вследствие значительных упрощений получаемый результат не всегда
оказывается удовлетворительным. Этот барьер качества преодолевается с помощью более
совершенных (и дорогостоящих по вычислениям) методов, например, с помощью метода
трассировки лучей и его вариаций.
8. Хранение графических данных
Графические данные традиционно подразделяются на два класса: векторные и
растровые.
В компьютерной графике векторные данные обычно используют для
представления прямых, многоугольников и кривых (или любых объектов, которые могут
быть созданы на их основе) с помощью определенных в численном виде контрольных
(ключевых) точек. Программа воспроизводит линии посредством соединения ключевых
точек. С векторными данными всегда связана информация об атрибутах (например, цвете
и толщине линии) и набор соглашений (или правил), позволяющий программе начертить
требуемые объекты.
41
Растровые данные представляют собой набор числовых значений, определяющих
цвета отдельных пикселей. Обычно говорят, что растр – это массив пикселей, хотя
технически растр является массивом числовых значений, задающих, окрашивающих или
«включающих» соответствующие пиксели при отображении образа на устройстве вывода.
8.1 Алгоритмы сжатия данных
Сжатие – это процесс, применяемый для уменьшения физического размера блока
информации. Работая с компьютерной графикой, мы заинтересованы в том, чтобы
уменьшить размер блока графических данных и таким образом поместить в заданное
физическое пространство больше информации. Сжатие можно применять и для того,
чтобы помещать большие изображения в блок памяти заданного размера.
Существует множество алгоритмов сжатия графической информации, однако
наиболее часто применяются лишь несколько из них. Большинство распространенных
схем являются вариантами методов:
группового кодирования (RLE);
Лемпела – Зива – Велча (LZW);
CCITT (один из типов этого сжатия является вариантом сжатия по алгоритму
Хаффмена);
дискретный косинус-преобразований (DCT), применяемого в JPEG-сжатии;
JBIG;
ART;
фрактального сжатия.
Сжатие растровых, векторных и метафайловых данных осуществляется по-
разному. В растровых файлах сжимаются только данные изображения; заголовок и все
остальные данные (таблица цветов, концовка и так далее) всегда остаются несжатыми.
Векторные файлы сжимаются редко, так как представление данных изображения в
компактной форме заложено в основу любого векторного формата. Схемы сжатия,
применяемые в метафайлах, часто похожи на схемы, используемые для сжатия растровых
изображений. Их выбор зависит от содержащейся в метафайле информации.
Важно уяснить, что алгоритмы сжатия не описывают определенный дисковый
файловый формат. Алгоритмы сжатия определяют только способ кодирования данных, но
не формат их записи на диск.
Групповое кодирование (RLE)
Групповое кодирование – алгоритм сжатия данных, поддерживаемый
большинством растровых файловых форматов, таких как TIFF, BMP и PCX. Алгоритм
RLE позволяет сжимать данные любых типов, невзирая на содержащуюся в них
информацию. Однако сама информация влияет на полноту сжатия. Хотя большинство
алгоритмов RLE не могут достигать высокой степени сжатия, характерной для более
совершенных алгоритмов, но групповое кодирование легко и быстро выполняется,
являясь хорошей альтернативой применению сложных алгоритмов сжатия или отказу от
использования таковых вообще.
RLE уменьшает физический размер повторяющихся строк символов. Такие
повторяющиеся строки, называемые группами, обычно кодируются в двух байтах. Первый
байт определяет количество символов в группе и называется счетчиком группы. На
практике закодированная группа может содержать от 1 до 128 или 256 символов, что
часто записывается в счетчик группы в виде: количество символов минус единица
42
(значение от 0 до 127 или 255). Второй байт группы содержит значение символа в группе,
которое находится в диапазоне от 0 до 255 и называется значением группы.
Несжатая символьная группа из 15 символов «А» обычно занимает 15 байт:
ААААААААААААААА
После RLE-кодирования та же строка займет всего два байта:
15А
Код 15А, сгенерированный для представления символьной строки называется RLE-
пакетом. Первый байт данного пакета (15) является счетчиком группы и содержит
количество повторений. Второй байт (А) служит значением группы и хранит повторяемое
значение.
Новый пакет генерируется каждый раз, когда изменяется группа или когда
количество символов в группе превышает максимальное значение счетчика.
Предположим, что наша 15-символьная строка теперь содержит четыре различных
символьных группы:
AAAAAAbbbXXXXXt
Применив групповое кодирование, мы сможем сжать ее в 4 двухбайтовых пакета:
6A3b5X1t
Таким образом, в результате группового кодирования 15-байтовая строка станет
занимать только 8 байт. В данном случае групповое кодирование позволило получить
степень сжатия, примерно равную 2:1.
В определенных типах данных длинные группы встречаются крайне редко.
Например, текст в формате ASCII редко включает длинные группы. В предыдущем
примере последняя группа (содержащая символ «t») имеет единичную длину, тем не
менее, это все же группа, следовательно, счетчик группы и значение группы будут
записаны в два байта. Для кодирования группы в RLE требуется как минимум два байта,
поэтому группы из одиночных символов займут больше памяти.
Схемы RLE просты и быстры, но эффективность сжатия зависит от типа данных
изображения, подлежащего кодированию. Черно-белые изображения, содержащие
значительно больше белого цвета, кодируются очень хорошо, поскольку включают
большие объемы непрерывных данных постоянного цвета. Однако сложные изображения
с большим количеством цветов, типа фотографий, кодируются весьма плохо. Причиной
тому является сложность изображения, а именно большое количество различных цветов и
относительно малое количество групп одинакового цвета.
LZW-сжатие
Схема сжатия Лемпела – Зива – Велча (LZW) является одной из наиболее
распространенных в компьютерной графике. Этот метод сжатия данных без потерь
применяется в различных форматах файлов изображений, в частности GIF и TIFF, и
включен в стандарт сжатия для модемов V.42bis и PostScript Level 2.
В 1977 году Абрахамом Лемпелом и Джекобом Зивом был создан первый
компрессор из широко известного сегодня семейства компрессоров LZ. Алгоритмы
сжатия LZ77 широко использовались для сжатия текста, а также стали основой таких
архивирующих программ как compress, lha, zoo, pkzip и arj. Алгоритмы сжатия LZ78 более
часто применялись для сжатия двоичных данных, например растровых.
В 1984 году, являясь сотрудником Unisys, Терри Велч модифицировал компрессор
LZ78 с учетом применения высокоскоростных дисковых контроллеров. Полученный в
результате алгоритм LZW широко используется и сегодня.
Алгоритм LZW позволяет работать с любым типом данных. Он обеспечивает
достаточно быстрое сжатие и распаковку данных, не требуя при этом выполнения
операций с плавающей запятой. Благодаря тому, что LZW пишет сжатые данные байтами,
43
а не словами, результат может быть идентичен и в системах с порядком байтов «старший
в младшем», и в системах с порядком байтов «младший в младшем».
Алгоритм LZW относится к алгоритмам подстановок, или базирующимся на
словарях. Этот алгоритм из данных входного потока строит словарь данных (также
называемый переводной таблицей или таблицей строк). Образцы данных (подстроки)
идентифицируются в потоке данных и сопоставляются с записями словаря. Если
подстрока не представлена в словаре, то на базе содержащихся в ней данных создается и
записывается в словарь кодовая фраза. Затем эта фраза записывается в выходной поток
сжатых данных.
Если эта подстрока встречается во входном потоке повторно, фраза,
соответствующая ей, читается из словаря и записывается в выходной поток. Поскольку
такая фраза имеет меньший физический размер, чем подстрока, которую она
представляет, мы говорим, что произошло сжатие данных.
Декодирование LZW-данных осуществляется в порядке, обратном кодированию.
Ряд файловых форматов, в том числе и TIFF, применяют подобный метод
кодирования для графических файлов. В TIFF пиксельные данные пакуются в байты до
того, как поступают на вход LZW. Следовательно исходный байт LZW может быть
пиксельным значением, частью пиксельного значения или несколькими пиксельными
значениями (в зависимости от битовой глубины изображения и количества цветовых
каналов).
GIF требует, чтобы каждый входной символ LZW был пиксельным значением.
Поскольку GIF позволяет сохранять глубину изображений от 1 до 8 битов, то в нем могут
существовать от 2 до 256 входных символов LZW и словарь LZW инициализируется
соответствующим образом. Не имеет значения, как были упакованы пиксели в оригинале
– LZW будет работать с ними как с последовательностью символов.
8.2 Пример форматов графических файлов
Microsoft Windows Bitmap
BMP (Bitmap Picture) – это собственный растровый формат Windows, который
используется для хранения практически всех типов растровых данных. Большинство
приложений, работающих с графикой в среде Microsoft Windows поддерживают создание
и отображение файлов в формате BMP. Он очень популярен в операционной системе MS-
DOS, является «родным» форматом растровых файлов для системы OS/2.
На рисунке 9.2.1 показана структура файла BMP.
44
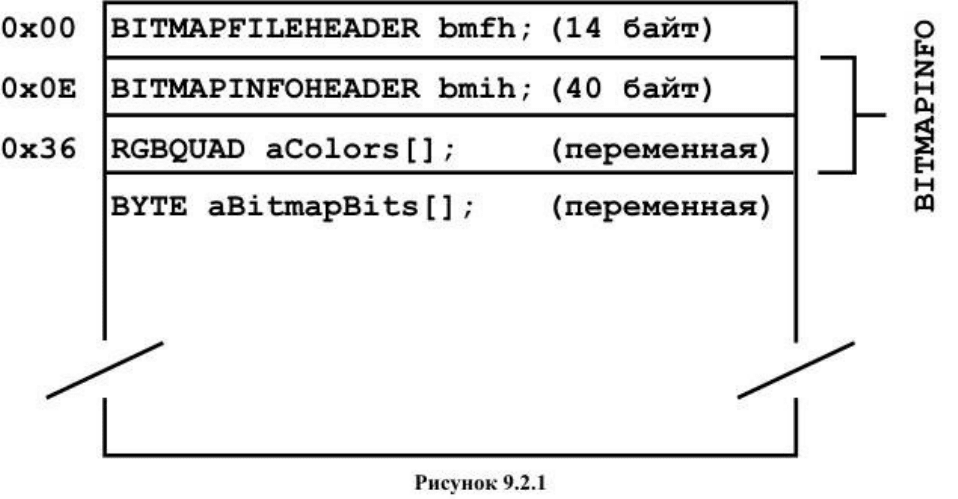
Первым элементом любого BMP-файла является заголовок BITMAPFILEHEADER.
Как показано на рисунке 9.2.1 он занимает ровно 14 байт.
typedef struct tagBITMAPFILEHEADER
{
UINT bfType;
DWORD bfSize;
UINT bfReserved1;
UINT bfReserved2;
DWORD bfOffBits;
} BITMAPFILEHEADER;
bfType – должен содержать два ASCII-символа: «B» и «M», разумеется
означающие bitmap. Соответствующие шестнадцатеричные значения равны 0x42 и
0x4D. При других значениях этого поля файл не является растровым
изображением, принятым в Windows.
bfSize – равен размеру файла в байтах, как указано в соответствующем элементе
оглавления дискового каталога. Используется для проверки целостности файла и
для распределения памяти под весь файл.
bfReserved1 и bfReserved2 – не документировано и не используется, должно быть
равно 0.
bfOffBits – специфицирует байтовое смещение до начала растрового изображения.
Используется для определения местонахождения массива aBitmapBits в файле.
В целях безопасности для идентификации BMP-файла поля bfType и bfSize обычно
используются вместе. Если bfType содержит символы «B» и «M», а bfSize не равен длине
файла, то это не BMP-файл. Этот прием предотвращает ошибки, возникающие при
попытке отобразить другой файл как картинку, например текстовый файл, начинающийся
с букв «B» и «M».
Следующей частью BMP-файла является структура BITMAPINFOHEADER,
которая полностью описывает растровое изображение. С помощью нее можно
подготовить растровое изображение к показу на экране, распаковке и прочим операциям.
typedef struct tagBITMAPINFOHEADER
{
DWORD biSize;
LONG biWidth;
LONG biHeight;
45

WORD biPlanes;
WORD biBitCount;
DWORD biCompression;
DWORD biSizeImage;
LONG biXPelsPerMeter;
LONG biYPelsPerMeter;
DWORD biClrUsed;
DWORD biClrImportant;
} BITMAPINFOHEADER;
biSize – специфицирует собственный размер структуры в байтах. Должен быть
равен 40 (0x28 в шестнадцатеричной системе). Если этот элемент структуры равен
12, то растровое изображение, вероятно, принадлежит системе OS/2.
biWidth и biHeight – содержат ширину и высоту изображения в пикселях
соответственно.
biPlanes – должен быть равен единице, так как BMP-файлы, какого бы типа они не
были, содержат только одну цветовую плоскость.
biBitCount – содержит число битов на пиксель. Кроме того, отличает монохромное
изображение от цветного. Должно быть равно 1, 4, 8 или 24. Обычно используется
в сочетании с biClrUsed и biClrImportant. В следующей таблице описываются
значения biBitCount и то, как они влияют на содержимое массива aColors.
biBitCount Действие
1 Помечает изображение как монохромное. Показывает, что массив aColors
содержит два элемента типа RGBQUAD. Каждый бит изображения,
хранимый в массиве aBitmapBits, служит индексом массива aColors. Бит,
равный 0, окрашен в соответствии с содержимым bmiColors[0], единичный
бит – в соответствии с содержимым bmiColors[1]. Программа не должна
предполагать, что монохромные пиксели непосредственно представляют
белый и черный цвета, хотя часто так оно и есть.
4 Показывает, что массив aColors содержит до 14 цветовых значений типа
RGBQUAD. В этом формате каждый байт содержит два четырехбитовых
пикселя, а каждый пиксель есть индекс массива aColors, определяющего
цвет. Например, байт изображения, равный 0x23, содержит два пикселя, один
из которых равен 0x02, а второй – 0x03. Цвет первого пикселя равен
aColors[0x02], а цвет другого aColors[0x03].
8 Показывает, что массив aColors содержит до 256 цветовых значений типа
RGBQUAD. Каждый байт в массиве aBitmapBits представляет собой
отдельный пиксель, являющийся индексом массива. Цвет любого пикселя q
равен aColors[q].
24 Этот формат может описывать изображение с более чем 16-ю миллионами
цветовых оттенков. Иногда называемые полноцветными (true color), эти
изображения обычно используются для представления фотографий. В
данном формате массив aColors отсутствует. Вместо этого 24-разрядные
значения массива aBitmapBits представляют каждый пиксель как красно-
зелено-синюю триаду (тип RGBTRIPLE). BMP-файл этого типа может
занимать огромное пространство на диске и в памяти.
biCompression – показывает, хранится ли данное изображение в сжатом виде, а
также метод его упаковки. Равен BI_RGB (изображение не сжато), BI_RLE8 (8-
разрядное групповое кодирование) или BI_RLE4 (4-разрядное групповое
кодирование).
biSizeImage – содержит размер растрового изображения в байтах. Может быть
нулевым, если biCompression равно BI_RGB.
46
biXPelsPerMeter, biYPelsPerMeter – указывают предпочтительное разрешение в
пикселях на метр по горизонтали и вертикали соответственно. Теоретически чем
ближе разрешающая способность устройства отображения соответствует этим
параметрам, тем лучше будет выглядеть изображение на экране. На практике эти
параметры используются редко.
biClrUsed – обычно содержит число цветов, используемое в растровом
изображении и определяемое массивом aColors типа RGBQUAD. Если biClrUsed
равен 0, как это обычно и бывает, в изображении используется максимальное
количество цветов, возможное для изображения данного типа.
biClrImportant – содержит число важных цветов изображения. Например, если это
значение равно 3, первые три значения цвета в массиве aColors должны
отображаться на экране с как можно более точным соответствием. Другие пиксели
могут отображаться с измененным цветом или безболезненно пропускаться. Если
biClrImportant равен 0, все цвета считаются важными. Этот параметр не имеет
смысла для растровых изображений с 24-разрядным представлением цвета.
Как было отмечено выше пиксели растрового изображения в общем случае
являются индексами массива цветовых значений типа RGBQUAD. Цветовое значение
представляет собой трехбайтовую композицию интенсивностей красного, зеленого и
синего цветов. Четвертый байт дополняет структуру таким образом, что каждый элемент в
RGBQUAD-массиве начинается с четного адреса. Хотя это несколько расточительно,
данная схема сильно повышает производительность, так как процессоры Intel могут
выбирать выровненные на четную границу данные быстрее.
В BMP-файле элемент aBitmapBits (если таковой вообще присутствует) содержит
массив структур типа RGBQUAD.
typedef struct tagRGBQUAD
{
BYTE rgbBlue;
BYTE rgbGreen;
BYTE rgbRed;
BYTE rgbReserved;
} RGBQUAD;
rgbBlue – содержит относительную интенсивность синего цвета от 0 до 255.
rgbGreen – содержит относительную интенсивность зеленого цвета от 0 до 255.
rgbRed – содержит относительную интенсивность красного цвета от 0 до 255.
rgbReserved – не используется. Предполагается равным 0, хотя, его физическое
значение не важно.
Как было отмечено выше массив aBitmapBits содержит пиксели, которые
различаются по формату в зависимости от типа растрового изображения. Кроме того,
байты могут быть сжаты. Байты хранятся строками слева направо, а каждая строка
представляет собой линию развертки (scan line), которая может быть дополнена до 32-
разрядной границы. Линии развертки упорядочены снизу вверх, то есть первый элемент
массива содержит пиксели последней строки изображения. В растровых изображениях с
24-разрядным представлением цвета, где массив aColors отсутствует, байты aBitmapBits
непосредственно представляют 24-разрядные триадные цвета пикселей. В других
растровых изображениях пиксели из aBitmapBits представляют собой индексы массива
aColors.
47
Глоссарий
Аффинные преобразования—масштабирование, перенос, отражение или поворот
геометрического объекта на плоскости или в пространстве.
Векторная графика—способ описания изображения, при котором все объекты сцены
задаются в виде координат их вершин.
Воксель (вогель)—пиксель в трехмерном пространстве.
Выпуклый многоугольник—многоугольник, все диагонали которого лежат внутри его
границы.
Когнитивная графика—генерация изображений по их неформальному описанию (как
правило по описанию на естественном языке).
Пиксель—минимальная единица растрового изображения.
Растровая графика—способ описания изображения, в виде последовательности цветных
точек без выделения конкретных геометрических объектов.
Текстура—одномерное или двумерное изображение «наклеиваемое» на плоский или
трехмерный объект для придания большей реалистичности.
Трассировка лучей—метод построения трехмерных изображений, при котором
изображаемые пиксели и их цвет определяются с помощью слежения за лучами от
источника света.
Триангуляция—декомпозиция произвольного многоугольника на треугольники.
48
Литература
1. Шикин Е.В., Боресков А.В. «Компьютерная графика.» - М.: "Диалог-МИФИ", 1995.
2. «Красота фракталов.» - М.: Мир, 1994.
3. Джеймс Д. Мюррей, Уильям ван Райпер «Энциклопедия форматов графических
файлов» - К.: BHV, 1997.
4. Том Сван «Форматы файлов Windows» - М.: Binom, 1995.
5. Борзенко А., Федоров А. «Мультимедиа для всех.» - М.: "Компьютер-пресс", 1995.
6. Корриган Д. «Компьютерная графика. Секреты и решения.» - М.: "Энтроп", 1995.
7. «Мультимедиа.» Под ред. Петренко А.И. - М., БИНОМ, 1994.
49