Стронгин Р.Г (ред.) Высокопроизводительные параллельные вычисления на кластерных системах
Подождите немного. Документ загружается.



Федеральное агентство по образованию
Нижегородский государственный университет
им. Н.И. Лобачевского
ВЫСОКОПРОИЗВОДИТЕЛЬНЫЕ
ПАРАЛЛЕЛЬНЫЕ ВЫЧИСЛЕНИЯ
НА КЛАСТЕРНЫХ СИСТЕМАХ
Материалы Седьмой Международной
конференции-семинара
(Нижний Новгород, 26–30 ноября 2007 г.)
Нижний Новгород
Издательство Нижегородского госуниверситета
2007

УДК 681.3.012:51
ББК 32.973.26–018.2:22
В 93
В 93 Высокопроизводительные параллельные вычисления на
кластерных системах. Материалы Седьмой Международной
конференции-семинара. – Нижний Новгород: Изд-во Нижегородского
госуниверситета, 2007. 443 с.
ISBN 978-5-91326-068-0
Редакционная коллегия:
Р.Г. Стронгин (отв. редактор), В.П. Гергель (зам.отв. редактора),
Д.И. Батищев, В.В. Воеводин, В.А. Гришагин, Ю.Г Евтушенко,
Л.В. Нестеренко, Я.Д. Сергеев, Б.Н. Четверушкин, В.И. Швецов
Сборник материалов Седьмой Международной конференции-семинара,
состоявшейся в Нижегородском государственном университете им. Н.И. Лобачевского
26–30 ноября 2007 г., содержит доклады, посвященные теоретической и практической
проблематике параллельных вычислений, ориентированных на использование
современных многопроцессорных архитектур кластерного типа.
ISBN 978-5-91326-068-0 ББК 32.973.26–018.2:22
Конференция организована в рамках Инновационной образовательной
программы ННГУ: Образовательно-научный центр
«Информационно-телекоммуникационные системы:
физические основы и математическое обеспечение»
Поддержка конференции
Российский фонд фундаментальных исследований
Компания Intel Technologies
Компания IBM
Компания Т-Платформы
© Нижегородский государственный
университет им. Н.И. Лобачевского, 2007
4
ПРЕДИСЛОВИЕ
26–30 ноября 2007 года Нижегородский государственный
университет им. Н.И. Лобачевского (учредитель), Вычислительный
центр РАН, Институт математического моделирования РАН при
поддержке компании Интел и Нижегородского фонда содействия
образованию и исследованиям провели в Нижнем Новгороде Седьмую
Международную конференцию-семинар и Всероссийскую
молодежную школу «Высокопроизводительные параллельные
вычисления на кластерных системах».
Главной задачей проведения
конференции и школы было
обсуждение основных аспектов организации высокопроизводительных
вычислений в кластерных компьютерных системах, активизации
научно-практической деятельности исследователей в этой
перспективной области развития современных средств
вычислительной техники, обмен опытом учебно-образовательной
деятельности при подготовке специалистов в области параллельных
вычислений.
На конференции рассмотрены следующие вопросы параллельных
вычислений:
принципы построения
кластерных вычислительных систем;
методы управления параллельными вычислениями в
кластерных системах;
параллельные алгоритмы решения сложных вычислительных
задач;
программные среды и средства для разработки параллельных
программ;
прикладные программные системы параллельных
вычислений;
методы анализа и оценки эффективности параллельных
программ;
подготовка специалистов в области параллельных
вычислений.
Материалы сборника
включают как доклады, так и тезисы
докладов (публикуются частично в авторской редакции).
Проведение конференции поддержано грантом РФФИ
№ 07-01-06123.
5
СИСТЕМА СВЯЗИ НА ГРАФИЧЕСКОМ ПРОЦЕССОРЕ
А.И. Акапьев
Нижегородский государственный технический университет
Введение
Последние пять лет наблюдается значительный рост
производительности процессоров графических плат. Начиная с 2003
года чистая вычислительная мощность графических плат превышает
вычислительную мощность центрального процессора. Также стоит
отметить, что темпы наращивания вычислительной мощности
графических чипов значительно выше, чем ядер
центральных
процессоров. Почему же столь значительные вычислительные
возможности не были использованы ранее для задач, отличных от
обработки графики? На это есть множество причин. Во-первых,
программирование графических чипов рассматривалось только с
позиций обработки графики, поэтому для неграфических задач
требовалось использовать графически ориентированный интерфейс
программирования. Во-вторых, узкая специализация под обработку
только
графической информации позволяла применять
вычислительные операции и хранение данных в памяти с малой
точностью, что для графических приложений было приемлемо, а для
задач расчётов и компьютерного моделирования – нет. Со временем
точность выполнения вычислений и хранения численных значений
увеличивалась, разрабатывались программы расчётов с
использованием графического интерфейса программирования. Летом
2006 года компания AMD/ATI первая
открыла неграфически
ориентированный интерфейс программирования, в ноябре 2006 года
следом последовала NVIDIA. С этого момента точность вычислений
стала достаточной для многих задач, а использование неграфического
программного интерфейса позволило заметно облегчить
программирование.
Так как современные алгоритмы обработки сигналов для
осуществления беспроводной связи требуют объёмных вычислений,
которые обычно реализуются на ПЛИС, то использование мощного
унифицированного оборудования, такого как современная видеокарта,
выглядит очень привлекательно.
6
В докладе показано, каким образом можно использовать
вычислительные возможности современных графических процессоров,
на примере реализации системы связи MIMO.
Особенности архитектуры графических процессоров
Современные графические процессоры являются
высокопараллельными вычислительными устройствами. Мы будем
ориентироваться на графические процессоры серии G80 фирмы
NVIDIA.
Большая производительность достигается за счёт использования
массива мультипроцессоров, где каждый мультипроцессор состоит из
набора
SIMD (Single Instruction Multiple Data – одна инструкция, много
данных) процессоров.
Пользовательский интерфейс организован таким образом, что
пользователю необходимо распределять вычислительную нагрузку как
по мультипроцессорам, так и по отдельным SIMD-процессорам
каждого мультипроцессора.
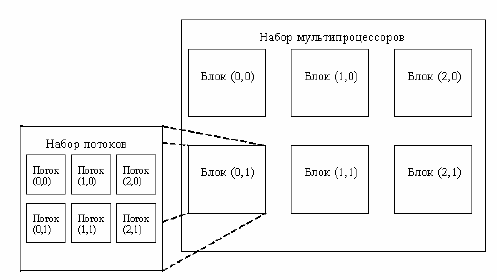
Структурная схема описываемой модели вычислений представлена
на рис. 1.
Рис. 1. Структурная схема модели вычислений на графических чипах G80
Схема работы программы на графическом процессоре следующая:
Из основной памяти компьютера в память графической карты
загружается программа, созданная пользователем;
Пользователь задаёт количество блоков и потоков в каждом блоке
(число потоков для всех блоков одинаково);
Программа одновременно исполняется всеми потоками каждого блока;
7
Определение, над какой частью данных работает каждый поток,
осуществляется на основе номера блока и номера потока в блоке;
По завершении работы всех созданных потоков пользователь копирует
результат вычислений из памяти графической платы в основную
память компьютера.
Подход к написанию программ для графического процессора
сильно отличается от подхода, применяемого при написании
программ
для последовательного процессора. При программировании с
использованием множества потоков требуется тщательно планировать
синхронизации параллельно исполняющихся потоков и эффективно
использовать иерархию памяти, управление которой отчасти
контролируется программистом (на графической плате присутствуют
несколько модулей памяти большого объема с медленным доступом и
несколько модулей памяти с быстрым доступом, но имеющих малый
объем). При
написании программ для последовательного процессора
нет необходимости в синхронизации, так как исполняется только один
поток программы. Контроль над использованием иерархической
памяти полностью осуществляется компилятором, используемым при
сборке программы.
Для эффективного использования данной системы необходимо
переосмысление алгоритмов обработки данных. В докладе показано,
каким образом можно реализовать симулятор MIMO-системы на
графическом чипе.
Программирование протоколов беспроводной связи
Современные беспроводные протоколы используют ресурсоёмкие
алгоритмы обработки сигналов. Наибольшую нагрузку на
вычислительную систему создают алгоритмы физического уровня (по
модели открытых систем OSI), такие как алгоритмы демодулятора и
декодера. Перенесение данных алгоритмов на графические
(многоядерные) процессоры может позволить избавиться от
специализированных и дорогих сигнальных процессоров. Для
выяснения пригодности
использования графических процессоров в
реальных задачах обработки сигналов был разработан набор программ,
позволяющих тестировать различные алгоритмы в условиях,
приближенных к реальным. В данной системе трафик любого сетевого
приложения, работающего на ОС Windows, можно направить на
обработку через графический чип, на котором реализована система
8
связи. Таким образом, разрабатываемые алгоритмы тестируются при
использовании реальных приложений и моделей трафика.
Архитектура тестовой системы
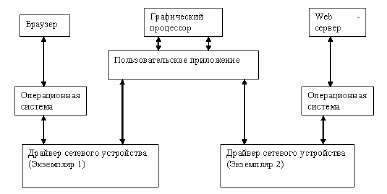
Принцип работы тестовой системы представлен на рис. 2. Здесь в
качестве примера изображено взаимодействие двух обычных сетевых
приложений, браузера и Web-сервера, запущенных на одном и том же
компьютере и передающих сетевые пакеты через тестовую систему.
Рис. 2. Принцип работы системы связи, реализованной на графическом
процессоре
Система состоит из двух основных компонентов:
1. Приложение, работающее в режиме пользователя;
2. Драйвер сетевого устройства.
Основная проблема, стоявшая перед разработчиком, заключалась в
перенаправлении трафика сетевых приложений, работающих под ОС
Windows, на обработку графическим процессором. Было решено
создать драйвер сетевой карты и сделать так, чтобы приложение
посылало сетевые пакеты через этот
драйвер. Также драйвер
необходим и для того, чтобы передавать сетевые пакеты,
пропущенные через разрабатываемую систему связи, обратно другому
сетевому приложению, работающему под ОС Windows.
На рис. 2 можно видеть, что браузер через операционную систему
передаёт данные драйверу сетевого устройства (экземпляр 1), а от
второго экземпляра драйвера данные через операционную систему
передаются Web-серверу.
Было
бы удобно работать с графическим чипом напрямую из
драйвера сетевого устройства и передавать данные от одного
экземпляра драйвера другому, но использование возможностей
9
графического чипа возможно лишь из режима пользователя, а драйвер
работает в режиме ядра. Именно для этих целей в схему был введен
еще один компонент – «Пользовательское приложение».
Пользовательское приложение взаимодействует с обоими
экземплярами драйверов и управляет работой графического
процессора. Так, данные, пришедшие от браузера, экземпляр 1
драйвера перенаправляет пользовательскому приложению, которое, в
свою очередь, отправляет их на обработку графическому процессору.
После того как графический процессор совершил необходимые
преобразования над данными (например, помехоустойчивое
кодирование, модуляция, симуляция влияния среды распространения,
демодуляция, декодирование), данные передаются через экземпляр 2
драйвера Web-серверу. Ответ Web-сервера следует в точности по
обратному пути.
MIMO-симулятор
В архитектуре тестовой системы, рассмотренной выше,
«Пользовательское
приложение» является тем звеном передачи
трафика, в которое возможно встраивание любых алгоритмов
обработки информации канального и физического уровней. В качестве
такого алгоритма был выбран алгоритм модулятора-демодулятора
MIMO (Multiple Input – Multiple Output) системы.
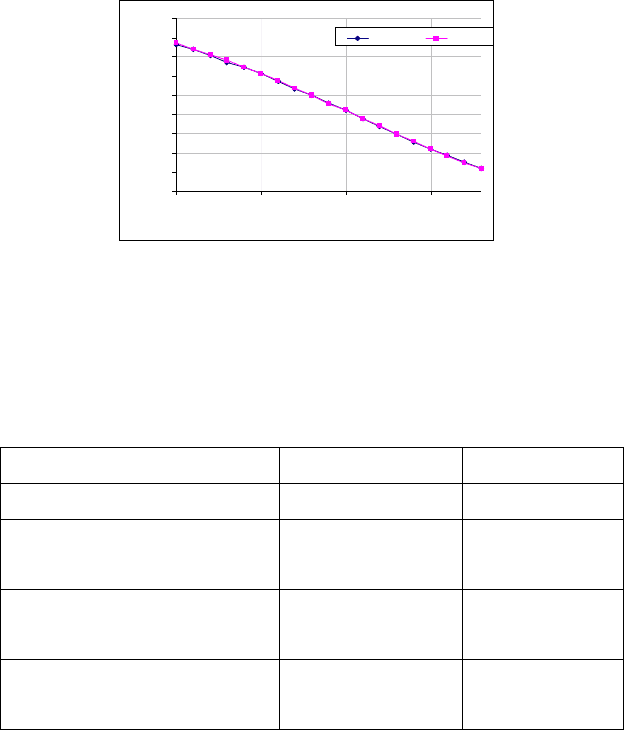
Реализованный на графическом чипе алгоритм, использующий M-
QAM модуляцию, был протестирован на корректность работы. На
рисунке 3 изображены кривые помехоустойчивости, полученные при
использовании алгоритмов,
реализованных на центральном
процессоре и графическом процессоре.
10
0
0,05
0,1
0,15
0,2
0,25
0,3
0,35
0,4
0,45
-6 -1 4 9
Отноше ние сигнал - шум, дБ
BE
R
CPU GPU
Рис. 3. Зависимость числа ошибок на бит переданной информации от
отношения сигнал-шум
Видим, что кривые помехоустойчивости для симулятора,
работающего на центральном процессоре, и симулятора,
исполняющегося на графическом процессоре, совпадают. Это
означает, что точность вычислений у обоих симуляторов одинакова.
Перейдем к сравнению скоростей работы обоих симуляторов.
CPU–симулятор GPU–симулятор
Модель аппаратуры Intel E6600 NVIDIA 8000 GTX
Время исполнения при передаче
1000 MIMO-символов, каждый из
которых имеет размер 192 бита, с
14.422 1.585
Время исполнения при передаче
1000 MIMO-символов, каждый из
которых имеет размер 256 бит, с
18.453 2.132
Время исполнения при передаче
1000 MIMO-символов, каждый из
которых имеет размер 512 бит, с
37.266 4.184
Таблица 1. Сравнение работы симуляторов
Из таблицы 1 видим, что производительность симулятора,
работающего на GPU, приблизительно в 8.5 раз выше, чем симулятора,
работающего на центральном процессоре.