Керниган Б., Пайк Р. Практика программирования
Подождите немного. Документ загружается.

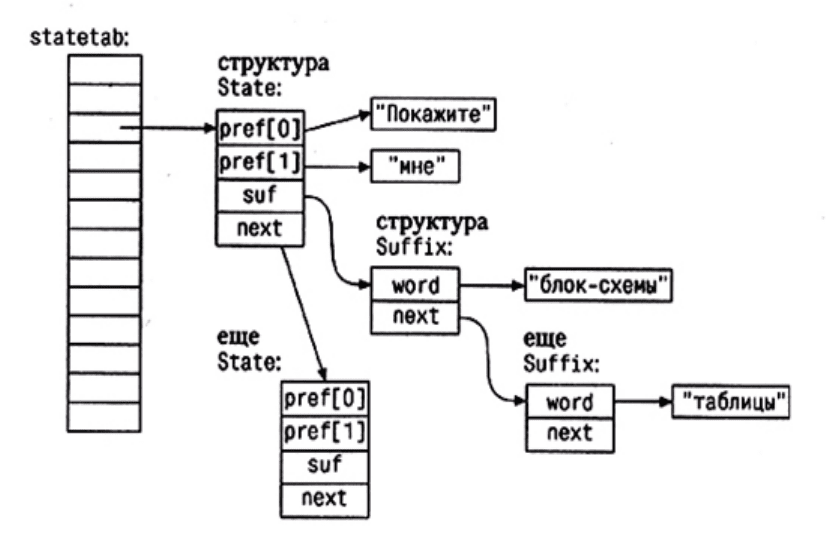
Нам потребуется хэш-функция для префиксов, которые являются массивами строк.
Нетрудно преобразовать хэш-функцию из главы 2, сделав цикл по строкам в
массиве, таким образом хэшируя конкатенацию этих строк:
/* hash: вычисляет хэш-значение
для массива из NPREF строк */
unsigned int hash(char *s[NPREF])
{
unsigned int h; unsigned char
*p;
int i;
/* hash: вычисляет хэш-значение
для массива из NPREF строк */
unsigned int hash(char *s[NPREF])
{
unsigned int h;
unsigned char *p;
int i;
Выполнив
схожим образом модификацию алгоритма lookup, мы завершим
реализацию хэш-таблицы:
/* lookup: ищет префикс;
создает его при необходимости. */
/* возвращает указатель, если
префикс существует или создан; *,
/* NULL в противном случае. */
/* при создании не делает strdup,
так что строки
/* не должны изменяться после
помещения в таблицу. */
State* lookup(char *prefix[NPREF],
int create)
{
int i, h;
State *sp;
h = hash(prefix);
for (sp = statetabfh]; sp != NULL;
sp = sp->next)
{ for (i = 0; i,< NPREF; i++)
if (strcmp(prefix[i], sp->pref[i]) != 0)
break;
if (i == NPREF) /* нашли'*/ return sp;
I> if (create) { sp = (State *)
emalloc(sizeof(State)); for
(i = 0; i < NPREF; i++)
sp->pref[i] = prefix[i]; sp->suf = NULL;
sp->next = statetabfh];
statetab[h] = sp; }
return sp; }
Обратите внимание на то, что lookup не создает копии входящей строки при
создании нового состояния, просто в sp->pref [ ] 'сохраняются указатели. Те, кто
использует вызов lookup, должны гарантировать, что впоследствии данные
изменены не будут. Например, если строки находятся в буфере ввода-вывода, то
перед тем, как
вызвать lookup, надо сделать их копию; в противном случае
следующие куски вводимого текста могут перезаписать данные, на которые
ссылается хэш-таблица. Необходимость решать, кто же владеет совместно
используемыми ресурсами, возникает достаточно часто. Эту тему мы подробно
рассмотрим в следующей главе.
Теперь нам надо прочитать файл и создать хэш-таблицу:
/* build; читает ввод,
создает таблицу префиксов */
void build(char *prefix[NPREF],
FILE *f)
{
char buf[100], fmt[10];
/* создать форматную строку:
%s может переполнить buf */ sprintf(fmt,
"%%%ds", sizeof(buf)-1); while
(fscanf(f, fmt, buf) != EOF)
add(prefix, estrdup(buf)); }
Необычный вызов sprintf связан с досадной проблемой, присущей f scant, — если бы
не эта проблема, функция f scanf идеально подошла бы для нашего случая. Все
дело в том, что вызов fscanf с форматом %s считывает следующее ограниченное
пробелами слово из файла в буфер, но без
проверки его длины: слишком длинное
слово может переполнить входной буфер, что приведет к разрушительным
последствиям. Если буфер имеет размер 100 байтов (что гораздо больше того, что
ожидаешь встретить в нормальном тексте), мы можем использовать формат %99s
(оставляя один байт на заключительный ' \0'), что будет означать для fscanf приказ
остановиться после 99 байт. Тогда длинное слово
окажется разбитым на части, что
некстати, но вполне безопасно. Мы могли бы написать
? enum { BUFSIZE = 100 };
? char fmtrj = "%99s"; /1 BUFSIZE-1 ./
однако это потребовало бы двух констант для одного, довольно произвольного
значения — размера буфера; обе эти константы пришлось бы поддерживать в
непротиворечивом состоянии. Проблему можно решить раз и навсегда, создавая
форматную строку динамически — с помощью sprintf, и именно так мы и поступили.
Аргументы build — массив prefix, содержащий предыдущие NPREF введенных слов и
указатель FILE. Массив prefix и
копия введенного слова передаются в add, которая
добавляет новый элемент в хэш-таблицу и обновляет префикс:
/* add: добавляет слово в
список суффиксов,
обновляет префикс */
void add(char *prefix[NPREF],
char *suffix) {
State *sp;
sp = lookup(prefix, 1);
/* создать, если не найден
*/ addsuffix(sp, suffix); /*
сдвиг слов вниз в префиксе */
memmove(prefix, prefix+1,
(NPREF-1)*sizeof(prefix[0]));
prefix[NPREF-1] = suffix;
}
Вызов memmove — идиоматический способ удаления из массива. В префиксе
элементы с 1 по NPREF-1 сдвигаются вниз на
позиции с 0 по NPREF-2, удаляя
первое слово и освобождая место для нового слова в конце.
Функция addsuf fix добавляет новый суффикс:
/* addsuffix: добавляет
в состояние. */
/* Суффикс впоследствии не
должен меняться */
void addsuffix
(State *sp, char *suffix)
{
Suffix *suf;
suf = (Suffix *) emalloc
(sizeof(Suffix)); suf->word =
suffix; suf->next = sp->suf; sp->suf = suf;
}
Мы разделили процесс обновления состояния на две функции — add просто
добавляет суффикс к префиксу, тогда как addsuffix выполняет тесно связанное с
реализацией действие — добавляет слово в список суффиксов. Функция add
вызывается из build, но addsuffix используется только изнутри add — это та часть
кода, которая может быть впоследствии изменена, поэтому лучше выделить ее в
отдельную функцию, даже если вызываться она будет лишь из одного места.
Генерация вывода
Теперь, когда структура данных построена, пора переходить к следующему шагу —
генерации нового текста. Основная идея остается неизменной: у нас есть префикс,
мы случайным образом выбираем один из возможных для него суффиксов, печатаем
его, затем обновляем префикс. Это повторяющаяся часть обработки; нам еще надо
продумать, как начинать и как заканчивать алгоритм. Начать
будет нетрудно, если
мы запомним слова первого префикса и начнем с них. Закончить алгоритм также
нетрудно; для этого нам понадобится слово-маркер. Прочтя весь вводимый текст,
мы можем добавить некий завершитель — "слово", которое с гарантией не
встретится ни в одном тексте:
build(prefix, stdin);
add(prefix, NONWORD);
В этом фрагменте NONWORD — некоторое значение, которое точно никогда
не
встретится в тексте. Поскольку по нашему определению слова разделяются
пробелами, на роль завершителя подойдет "слово", равносильное пробелу, но
отличное от него, например символ перевода строки:
char NONWORD[] = "\n"; /* никогда не встретится */
Еще одна проблема — что делать, если вводимого текста недостаточно для запуска
алгоритма? Для решения этой проблемы существуют два принципиальных подхода
— либо
прерывать работу программы, если введенного текста недостаточно, либо
считать, что для генерации хватит любого фрагмента, и просто не утруждать себя
проверкой. Для данной программы лучше выбрать второй подход.
Можно начать процесс генерации с создания фиктивного префикса, который даст
гарантию, что для работы программы всегда хватит вводимого текста. Для начала
можно
инициализировать все значения массива префиксов словом NONWORD. Это
даст дополнительное преимущество — первое слово во вводимом файле будет
первым суффиксом нашего вымышленного префикса, так что в генерирующем цикле
печатать надо будет только суффиксы.
На случай, если генерируемый текст окажется непредсказуемо большого размера,
можно встроить ограничитель — прерывать алгоритм после вывода заданного
количества слов или
при появлении NONWORD в качестве суффикса.
Добавление нескольких NONWORD в концы структур данных значительно упрощает
основные циклы программы — это хороший пример использования специальных
значений для маркировки границ — сигнальных меток (sentinel).
Как правило, надо стараться обработать все отклонения, исключения и особые
случаи непосредственно в данных. Код писать труднее, так что старайтесь добиться
того, чтобы
управляющая логика была как можно более проста и прямолинейна.
Функция generate использует алгоритм, который мы только что описали в общих
словах. Она генерирует текст по слову в строке; эти слова можно группировать в
более длинные строки при помощи любого текстового редактора — в главе 9 будет
показано простое средство для такого форматирования — процедура f mt.
Благодаря
использованию в начале и в конце строк NONWORD, generate начинает и
заканчивает работу без проблем:
/* generate: генерирует
вывод по одному слову в строке */
void generate(int nwords)
{
State *sp;
Suffix *suf;
char *prefix[NPREF], *w;
int i, nmatch; »
for (i = 0; i < NPREF; i++)
/* начальные префиксы
*/ prefix[i] = NONWORD;
for (i = 0; i < nwords; i++)
{ sp = lookup(prefix, 0); nmatch =
0; for (suf = sp->suf; suf != NULL; suf = suf->next)
if (rand() % ++nmatch == 0)
/* prob = 1/nmatch */
w = suf->word; if
(strcmp(w, NONWORD) == 0)
break;
printf("%s\n", w);
memmove(prefix, prefix+1,
(NPREF-1)*sizeof(prefix[0]));
prefix[NPREF-1] = w; } }
Обратите внимание на алгоритм случайного выбора элемента, когда число всех
элементов нам неизвестно. В переменной nmatch подсчитывается количество
совпадений при сканировании списка. Выражение
rand()
++nmatch == 0
увеличивает nmatch и является истинным с вероятностью 1/nmatch. Таким образом,
первый
подходящий элемент будет выбран с вероятностью 1, второй заменит его с
вероятностью 1/2, третий заменит выбранный из предыдущих с вероятностью 1/3 и т.
п. В каждый момент времени каждый из k просмотренных элементов будет выбран с
вероятностью i/k.
Вначале мы устанавливаем prefix в стартовое значение, которое с гарантией
присутствует в хэш-таблице. Первые найденные значения Suffix будут первыми
словами документа, поскольку только они следуют за стартовым префиксом. После
этого суффикс выбирается случайным образом. В цикле вызывается lookup для
поиска в хэш-таблице элемента (множества суффиксов), соответствующего данному
префиксу; после этого случайным образом выбирается один из суффиксов, он
печатается, а префикс обновляется.
Если выбранный суффикс оказывается NONWORD, то все заканчивается, поскольку
это означает, что мы достигли состояния, относящегося к концу введенного текста.
Если суффикс не NONWORD, то мы его печатаем, а далее с помощью вызова
memmove удаляем первое слово из префикса и делаем суффикс вторым словом
нового префикса, после чего цикл повторяется.
Теперь все написанное можно свести воедино в функцию main, которая читает
стандартный
ввод и генерирует не более заданного количества слов:
/* markov main: генерация
случайного текста */ /*
по алгоритму цепей Маркова */
int main(void) {
int i, nwords = MAXGEN;
char *prefix[NPREF]; /*
текущий вводимый префикс */
for (i = 0; i < NPREF; i++)
/* начальный префикс */
prefixfi] = NONWORD;
build(prefix, stdin);
add(prefix, NONWORD);
generate(nwords); return 0; }
На этом разработка программы на С завершена. В конце главы мы сравним
программы, написанные на разных языках. Главные достоинства С состоят в том,
что он предоставляет программисту возможность полного управления реализацией и
что программы, написанные
на С, работают, как правило, весьма быстро.
Расплачиваться за это приходится тем, что программист вынужден выполнять
большую работ}»;: он сам должен выделять и освобождать память, создавать хэш-
таблицы\1 связные списки и т. п. С — инструмент с остротой бритвы: с его помощью
можно создать и элегантную программу, и кровавое месиво.
Упражнение 3-1
Алгоритм случайного выбора элемента из списка неизвестной длины зависит от
качества генератора случайных чисел. Спроектируйте и осуществите эксперименты
для проверки метода на практике.
Упражнение 3-2
Если вводимые слова хранятся в отдельной хэш-таблице, то каждое слово окажется
записанным лишь единожды, следовательно — экономится место. Оцените, сколько
именно — измерьте какие-нибудь фрагменты текста. Подобная
организация
позволит нам сравнивать указатели, а не строки в хэш-цепочках префиксов, что
выполняется быстрее. Реализуйте этот вариант и оцените изменения в
быстродействии и размере используемой памяти.
Упражнение 3-3
Удалите выражения, которые помещают сигнальные метки NONWORD в начало и
конец данных, и измените generate так, чтобы она нормально запускалась и
останавливалась без их
использования. Убедитесь, что вывод корректен для О, 1, 2,
3 и 4 слов. Сравните код с использованием сигнальных меток и код без них.
Java
Вторую реализацию алгоритма markov мы создадим на языке Java. Объектно-
ориентированные языки вроде Java заставляют нас обращать особое внимание на
взаимодействие между компонентами программы. Эти компоненты инкапсулируются
в независимые элементы данных, называемые объектами или классами; с ними
ассоциированы функции, называемые методами.
Java имеет более богатую библиотеку, чем С. В частности, эта библиотека включает
в себя набор классов-контейнеров (container classes) для группировки существующих
объектов различными способами. В качестве примера можно привести класс Vector,
который представляет собой динамически растущий массив, где могут храниться
любые объекты типа Object. Другой пример— класс Hashtable, с помощью которого
можно сохранять и получать
значения одного типа, используя объекты другого типа
в качестве ключей.
В нашем приложении экземпляры класса Vector со строками в качестве объектов —
самый естественный способ хранения префиксов и суффиксов. Так же естественно
использовать и класс Hashtable, ключами в котором будут векторы префиксов, а
значениями — векторы суффиксов. Конструкции подобного рода называются
отображениями (тар) префиксов на
суффиксы; в Java нам не потребуется в явном
виде задавать тип State, поскольку Hashtable неявным образом сопоставляет
префиксы и суффиксы. Этот дизайн отличается от версии С, где мы создавали
структуры State, в которых соединялись префиксы и списки суффиксов, а для
получения структуры State использовали хэширование префикса.
Hashtable предоставляет в наше распоряжение метод put для хранения пар ключ
-
значение и метод get для получения значения по заданному ключу:
Hashtable h = new HashtableQ;
h.put(key, value);
Sometype v = (Sometype) h.get(key);
В нашей реализации будут три класса. Первый класс, Prefix, содер,-жит слова
префиксов:
class Prefix {
public Vector pref;
// NPREF смежных слов из ввода
...
Второй класс, Chain, считывает ввод, строит хэш-таблицу и генерирует вывод;
переменные класса выглядят так:
class Chain {
static final int NPREF = 2;
// размер префикса static
final String NONWORD = "\hf";
// "слово", которое
не может
встретиться в тексте Hashtable
statetab = new Hashtable();
// ключ = Prefix, значение =
suffix Vector Prefix prefix =
new Prefix(NPREF, NONWORD);
// начальный префикс Random rand =
new Random();
Третий класс — общедоступный интерфейс; в нем содержится функция main и
происходит начальная инициализация класса Chain:
class Markov {
static final int MAXGEN = 10000;
// максимальное количество
// генерируемых слов public static
void main(String[] args.) throws lOException
{
Chain chain = new ChainQ;
int nwords = MAXGEN;
chain.build(System.in);
chain.generate(nwords); } }
После того как создан экземпляр класса Chain, он в свою очередь создает хэш-
таблицу и устанавливает начальное значение префикса, состоящее из NPREF -
констант NONWORD. Функция build использует библиотечную функцию
StreamTokenizer для разбора вводимого текста на слова, разделенные пробелами.
Первые три вызова перед основным циклом устанавливают значения этой функции,
соответствующие нашему определению термина
"слово":
// Chain build: создает
таблицу
состояний из потока ввода
void build(InputStream in)
throws lOException
i
\
StreamTokenizer st = new
StreamTokenizer(in);
st.resetSyntax(); // удаляются правила
по умолчанию st.wordChars(0,
Character.MAX_VALUE); // включаются все
st.whitespaceChars(0, ' '); //литеры, кроме
пробелов while (st.nextToken() != st.TT_EOF)
add(st.sval); add(NONWORD);
}
Функция add получает из хэш-таблицы вектор суффиксов для текущего префикса;
если их не существует (вектор есть null), add создает новый вектор и новый префикс
для сохранения их в таблице. В
любом случае эта функция добавляет новое слово в
вектор суффиксов и обновляет префикс, удаляя из него первое слово и добавляя в
конец новое.
// Chain add: добавляет
слово в список суффиксов,
обновляет префикс
void add(String word)
{
Vector suf = (Vector)
statetab.get(prefix);
if (suf == null) {
suf = new Vector();
statetab.put(new Prefix(prefix),
suf);
}
suf.addElement(word);
prefix.pref.removeElementAt(O);
prefix, pref .addElement( word);
}
Обратите внимание на то, что если suf равен null, то add добавляет в хэш-таблицу
префикс как новый объект класса Pref ix, а не собственно pref ix. Это сделано
потому, что класс Hashtable хранит объекты по ссылкам, и если мы не сделаем
копию, то можем перезаписать данные в таблице. Собственно говоря, с этой
проблемой мы уже встречались
при написании программы на С.
Функция генерации похожа на аналогичную из программы на С, однако она
получается несколько компактнее, поскольку может случайным образом выбирать
индекс элемента вектора вместо того, чтобы в цикле обходить весь список.
// Chain generate: генерирует
выходной текст
void generate(int nwords)
{
prefix = new Prefix(NPREF,
NONWORD); for
(int i = 0; i < nwords; i++)
{Vector s = (Vector)
statetab.get(prefix); int r =Math.abs
(rand.nextlnt()) % s.size();
String suf = (String) s.elementAt(r);
if (suf.equals(NONWORD))break;
System.out.println
(suf);
prefix.pref.removeElementAt(O);
prefix.pref.addElement(suf);
}
}
Два конструктора Prefix создают новые экземпляры
класса в зависимости от
передаваемых параметров. В первом случае копируется существующее значение
типа Prefix, а во втором префикс создается из п копий строки; этот конструктор
используется для создания NPREF копий NONWORD при инициализации префикса:
// конструктор Prefix: создает
копию существующего префикса
Prefix(Prefix p)
{
pref = (Vector) p.pref.clone();
}
// конструктор Prefix: n копий строки
str Prefix(int n, String str)
{
pref = new Vector();
for (int i = 0; i < n; i++)
pref.addElement(str); }
Класс P refix имеет также два метода, hashCode и equals, которые неявно
вызываются из Hashtable для индексации и поиска по табллце. Нам пришлось
сделать Prefix полноценным классом как раз из-за этих двух методов, которых
требует Hashtable, иначе для него можно было бы использовать Vector, как мы
сделали с суффиксом.
Метод hashCode создает отдельно взятое хэш-значение, комбинируя набор
значений
hashCode для элементов вектора:
static final int MULTIPLIER =31;
// для hashCode()
// Prefix hashCode:
генерирует хэш-значение
// на основе всех слов префикса
public int hashCode()
{
int h = 0;
for
(int i = 0; i < pref.sizeO; i++)
h = MULTIPLIER *h + pref,elementAt(i).hashCode();
return h;
}
Метод equals осуществляет поэлементное сравнение слов в двух npeфиксах:
// Prefix equals:
сравнивает два префикса на
идентичность слов
public boolean equals(0bject о)
{
Prefix p = (Prefix) о;
for (int 1 = 0; i < pref.size(); i++)
if
(!pref.elementAt(i).equals
(p.pref.elementAt(i)))
return false; return true;
}
Программа на Java гораздо меньше, чем ее аналог на С, при
этом больше деталей
проработано в самом языке — очевидными примерами являются классы Vector и
Hashtable. В общем и целом управление хранением данных получилось более
простым, поскольку вектора растут, когда' нужно, а сборщик мусора (garbage collector
— специальный автоматический механизм виртуальной машины Java) сам заботится
об освобождении неиспользуемой памяти. Однако для того, чтобы использовать
класс Hashtable, нам пришлось-таки
самим писать функции hashCode и equals, так
что нельзя сказать, что язык Java заботился бы обо всех деталях.
Сравнивая способы, которыми программы на С и Java представляют < и
обрабатывают одни и те же структуры данных, следует отметить, что в версии на
Java лучше разделены функциональные обязанности. При таком подходе нам,
например, не составит большого труда
перейти от использования класса Vector к