Hager G., Wellein G. Introduction to High Performance Computing for Scientists and Engineers
Подождите немного. Документ загружается.


Distributed-memory parallel programming with MPI 215
root=1
count=4
op=MPI_SUM
Reduce
root=1
count=4
op=MPI_SUM
Reduce
root=1
count=4
op=MPI_SUM
Reduce
root=1
count=4
op=MPI_SUM
Reduce
sendbuf
recvbuf
0
2
3
sendbuf
sendbuf
sendbuf
1
+
+
+ +
Figure 9.4: A reduction
on an array of length
count (a sum in this
example) is performed
by MPI_Reduce().
Every process must
provide a send buffer.
The receive buffer ar-
gument is only used on
the root process. The
local copy on root can
be prevented by speci-
fying MPI_IN_PLACE
instead of a send buffer
address.
element-wise, using an operator encoded by the op argument, and stores the result in
recvbuf on root (see Figure 9.4). There are twelve predefined operators, the most
important being MPI_MAX, MPI_MIN, MPI_SUM and MPI_PROD, which imple-
ment the global maximum, minimum, sum, and product, respectively. User-defined
operators are also supported.
Now it is clear that the whole if ...else ...endif construct between lines
16 and 39 in Listing 9.3 (apart from printing the result in line 30) could have been
written as follows:
1 call MPI_Reduce(psum, & ! send buffer (partial result)
2 res, & ! recv buffer (final result @ root)
3 1, & ! array length
4 MPI_DOUBLE_PRECISION, &
5 MPI_SUM, & ! type of operation
6 0, & ! root (accumulate result there)
7 MPI_COMM_WORLD,ierror)
Although a receive buffer (the res variable here) must be specified on all ranks,
it is only relevant (and used) on root. Note that MPI_Reduce() in its plain form
requires separate send and receive buffers on the root process. If allowed by the
program semantics, the local accumulation on root can be simplified by setting the
sendbuf argument to the special constant MPI_IN_PLACE. recvbuf is then
used as the send buffer and gets overwritten with the global result. This can be good
for performance if count is large and the additional copy operation leads to signifi-
cant overhead. The behavior of the call on all nonroot processes is unchanged.
There are a few more global operations related to MPI_Reduce() worth noting.
216 Introduction to High Performance Computing for Scientists and Engineers
use bufWait()Isend(buf)Main thread
Auxiliary thread
buf)
post send operation, handshake, data transfer
do other work (not using
SYNC
time
Figure 9.5: Abstract timeline view of a nonblocking send (MPI_Isend()). Whether there is
actually an auxiliary thread is not specified by the standard; the whole data transfer may take
place during MPI_Wait() or any other MPI function.
For example, MPI_Allreduce() is a fusion of a reduction with a broadcast, and
MPI_Reduce_scatter() combines MPI_Reduce() with MPI_Scatter().
Note that collectives are not required to, but still may synchronize all processes
(the barrier is synchronizing by definition, of course). They are thus prone to similar
deadlock hazards as blocking point-to-point communication (see above).This means,
e.g., that collectives must be executed by all processes in the same order. See the MPI
standard document [P15] for examples.
In general it is a good idea to prefer collectives over point-to-point constructs
or combinations of simpler collectives that “emulate” the same semantics (see also
Figures 10.15 and 10.16 and the corresponding discussion in Section 10.4.4). Good
MPI implementations are optimized for data flow on collective communication and
(should) also have some knowledge about network topology built in.
9.2.4 Nonblocking point-to-point communication
All MPI functionalities described so far have the property that the call returns to
the user program only after the message transfer has progressed far enough so that the
send/receive buffer can be used without problems. This means that, received data has
arrived completely and sent data has left the buffer so that it can be safely modified
without inadvertentlychanging the message. In MPI terminology, this is called block-
ing communication. Although collective communication in MPI is always blocking
in the current MPI standard (version 2.2 at the time of writing), point-to-point com-
munication can be performed with nonblocking semantics as well. A nonblocking
point-to-point call merely initiates a message transmission and returns very quickly
to the user code. In an efficient implementation, waiting for data to arrive and the
actual data transfer occur in the background, leaving resources free for computation.
Synchronization is ruled out (see Figure 9.5 for a possible timeline of events for
the nonblocking MPI_Isend() call). In other words, nonblocking MPI is a way
in which communication may be overlapped with computation if implemented effi-
ciently. The message buffer must not be used as long as the user program has not
been notified that it is safe to do so (which can be checked by suitable MPI calls).
Nonblocking and blocking MPI calls are mutually compatible, i.e., a message sent
via a blocking send can be matched by a nonblocking receive.

Distributed-memory parallel programming with MPI 217
The most important nonblocking send is MPI_Isend():
1 <type> buf(
*
)
2 integer :: count, datatype, dest, tag, comm, request, ierror
3 call MPI_Isend(buf, ! message buffer
4 count, ! # of items
5 datatype, ! MPI data type
6 dest, ! destination rank
7 tag, ! message tag
8 comm, ! communicator
9 request, ! request handle (MPI_Request
*
in C)
10 ierror) ! return value
As opposed to the blocking send (see page 208), MPI_Isend() has an additional
output argument, the request handle. It serves as an identifier by which the pro-
gram can later refer to the “pending” communication request (in C, it is of type
struct MPI_Request). Correspondingly, MPI_Irecv() initiates a nonblock-
ing receive:
1 <type> buf(
*
)
2 integer :: count, datatype, source, tag, comm, request, ierror
3 call MPI_Irecv(buf, ! message buffer
4 count, ! # of items
5 datatype, ! MPI data type
6 source, ! source rank
7 tag, ! message tag
8 comm, ! communicator
9 request, ! request handle
10 ierror) ! return value
The status object known from MPI_Recv() is missing here, because it is not
needed; after all, no actual communication has taken place when the call returns to
the user code. Checking a pending communication for completion can be done via the
MPI_Test() and MPI_Wait() functions. The former only tests for completion
and returns a flag, while the latter blocks until the buffer can be used:
1 logical :: flag
2 integer :: request, status(MPI_STATUS_SIZE), ierror
3 call MPI_Test(request, ! pending request handle
4 flag, ! true if request complete (int
*
in C)
5 status, ! status object
6 ierror) ! return value
7 call MPI_Wait(request, ! pending request handle
8 status, ! status object
9 ierror) ! return value
The status object contains useful information only if the pending communication
is a completed receive (i.e., in the case of MPI_Test() the value of flag must be
true). In this sense, the sequence
1 call MPI_Irecv(buf, count, datatype, source, tag, comm, &
2 request, ierror)
3 call MPI_Wait(request, status, ierror)

218 Introduction to High Performance Computing for Scientists and Engineers
is completely equivalent to a standard MPI_Recv().
A potential problem with nonblocking MPI is that a compiler has no way to know
that MPI_Wait() can (and usually will) modify the contents of buf. Hence, in the
following code, the compiler may consider it legal to move the final statement in line
3 before the call to MPI_Wait():
1 call MPI_Irecv(buf, ..., request, ...)
2 call MPI_Wait(request, status, ...)
3 buf(1) = buf(1) + 1
This will certainly lead to a race condition and the contents of buf may be wrong.
The inherent connection between the MPI_Irecv() and MPI_Wait() calls, me-
diated by the request handle, is invisible to the compiler, and the fact that buf is not
contained in the argument list of MPI_Wait() is sufficient to assume that the code
modification is legal. A simple way to avoid this situation is to put the variable (or
buffer) into a COMMON block, so that potentially all subroutines may modify it. See
the MPI standard [P15] for alternatives.
Multiple requests can be pending at any time, which is another great advantage
of nonblocking communication. Sometimes a group of requests belongs together in
some respect, and one would like to check not one, but any one, any number, or all
of them for completion. This can be done with suitable calls that are parameterized
with an array of handles. As an example we choose the MPI_Waitall() routine:
1 integer :: count, requests(
*
)
2 integer :: statuses(MPI_STATUS_SIZE,
*
), ierror
3 call MPI_Waitall(count, ! number of requests
4 requests, ! request handle array
5 statuses, ! statuses array (MPI_Status
*
in C)
6 ierror) ! return value
This call returns only after all the pending requests have been completed. The status
objects are available in array_of_statuses(:,:).
The integration example in Listing 9.3 can make use of nonblocking communi-
cation by overlapping the local interval integration on rank 0 with receiving results
from the other ranks. Unfortunately, collectives cannot be used here because there
are no nonblocking collectives in MPI. Listing 9.4 shows a possible solution. The
reduction operation has to be done manually (lines 33–35), as in the original code.
Array sizes for the status and request arrays are not known at compile time, hence
those must be allocated dynamically, as well as separate receive buffers for all ranks
except 0 (lines 11–13). The collection of partial results is performed with a single
MPI_Waitall() in line 32. Nothing needs to be changed on the nonroot ranks;
MPI_Send() is sufficient to communicate the partial results (line 39).
Nonblocking communication provides an obvious way to overlap communica-
tion, i.e., overhead, with useful work. The possible performance advantage, however,
depends on many factors, and may even be nonexistent (see Section 10.4.3 for a
discussion). But even if there is no real overlap, multiple outstanding nonblocking
requests may improve performance because the MPI library can decide which of
them gets serviced first.

Distributed-memory parallel programming with MPI 219
Listing 9.4: Program fragment for parallel integration in MPI, using nonblocking point-to-
point communication.
1 integer, allocatable, dimension(:,:) :: statuses
2 integer, allocatable, dimension(:) :: requests
3 double precision, allocatable, dimension(:) :: tmp
4 call MPI_Comm_size(MPI_COMM_WORLD, size, ierror)
5 call MPI_Comm_rank(MPI_COMM_WORLD, rank, ierror)
6
7 ! integration limits
8 a=0.d0 ; b=2.d0 ; res=0.d0
9
10 if(rank.eq.0) then
11 allocate(statuses(MPI_STATUS_SIZE, size-1))
12 allocate(requests(size-1))
13 allocate(tmp(size-1))
14 ! pre-post nonblocking receives
15 do i=1,size-1
16 call MPI_Irecv(tmp(i), 1, MPI_DOUBLE_PRECISION, &
17 i, 0, MPI_COMM_WORLD, &
18 requests(i), ierror)
19 enddo
20 endif
21
22 ! limits for "me"
23 mya=a+rank
*
(b-a)/size
24 myb=mya+(b-a)/size
25
26 ! integrate f(x) over my own chunk - actual work
27 psum = integrate(mya,myb)
28
29 ! rank 0 collects partial results
30 if(rank.eq.0) then
31 res=psum
32 call MPI_Waitall(size-1, requests, statuses, ierror)
33 do i=1,size-1
34 res=res+tmp(i)
35 enddo
36 write (
*
,
*
) ’Result: ’,res
37 ! ranks != 0 send their results to rank 0
38 else
39 call MPI_Send(psum, 1, &
40 MPI_DOUBLE_PRECISION, 0, 0, &
41 MPI_COMM_WORLD,ierror)
42 endif

220 Introduction to High Performance Computing for Scientists and Engineers
Point-to-point Collective
Blocking
MPI_Send()
MPI_Ssend()
MPI_Bsend()
MPI_Recv()
MPI_Barrier()
MPI_Bcast()
MPI_Scatter()/
MPI_Gather()
MPI_Reduce()
MPI_Reduce_scatter()
MPI_Allreduce()
Nonblocking
MPI_Isend()
MPI_Irecv()
MPI_Wait()/MPI_Test()
MPI_Waitany()/
MPI_Testany()
MPI_Waitsome()/
MPI_Testsome()
MPI_Waitall()/
MPI_Testall()
N/A
Table 9.3: MPI’s communication modes and a nonexhaustive overview of the corresponding
subroutines.
Table 9.3 gives an overview of available communication modes in MPI, and the
most important library functions.
9.2.5 Virtual topologies
We have outlined the principles of domain decomposition as an example for data
parallelism in Section 5.2.1. Using the MPI functions covered so far, it is entirely
possible to implement domain decomposition on distributed-memory parallel com-
puters. However, setting up the process grid and keeping track of which ranks have to
exchange halo data is nontrivial. Since domain decomposition is such an important
pattern, MPI contains some functionality to support this recurring task in the form
of virtual topologies. These provide a convenient process naming scheme, which
fits the required communication pattern. Moreover, they potentially allow the MPI li-
brary to optimize communications by employing knowledgeabout network topology.
Although arbitrary graph topologies can be described with MPI, we restrict ourselves
to Cartesian topologies here.
As an example, assume there is a simulation that handles a big double precision
array P(1:3000,1:4000) containing 3000×4000=1.2×10
7
words. The simula-
tion runs on 3×4 = 12 processes,across which thearray is distributed “naturally,” i.e.,
each process holds a chunk of size 1000×1000. Figure 9.6 shows a possible Carte-
sian topology that reflects this situation: Each process can either be identified by its
rank or its Cartesian coordinates. It has a number of neighbors, which depends on
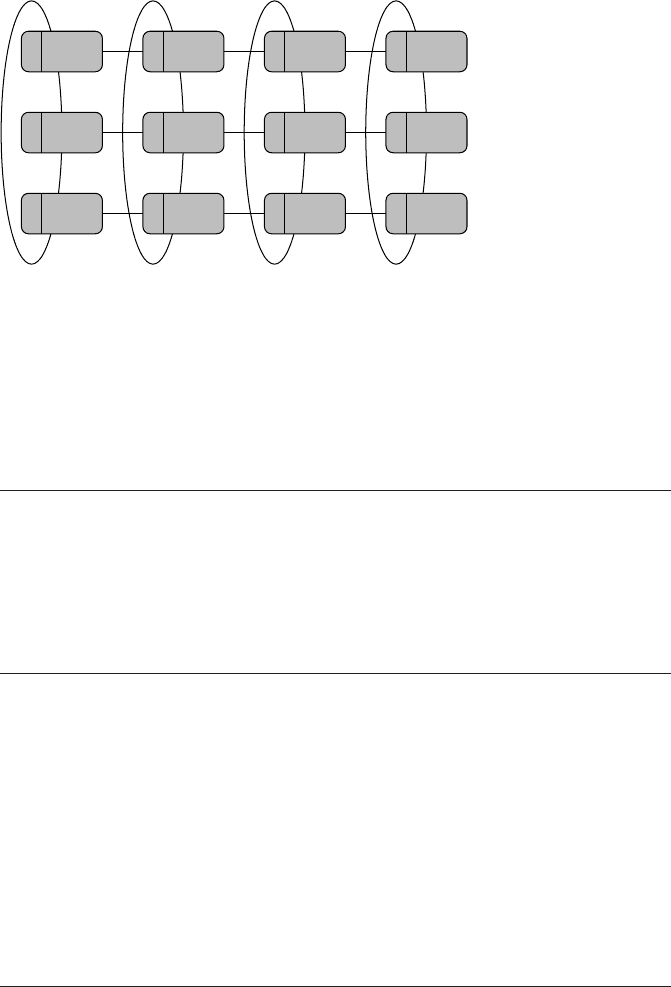
Distributed-memory parallel programming with MPI 221
0 (0,0)
2 (0,2)
4 (1,1)
5 (1,2)
3 (1,0) 6 (2,0) 9 (3,0)
10 (3,1)7 (2,1)
11 (3,2)8 (2,2)
1 (0,1)
Figure 9.6: Two-dimen-
sional Cartesian topol-
ogy: 12 processes form
a 3×4 grid, which is pe-
riodic in the second di-
mension but not in the
first. The mapping be-
tween MPI ranks and
Cartesian coordinates is
shown.
the grid’s dimensionality. In our example, the number of dimensions is two, which
leads to at most four neighbors per process. Boundary conditions on each dimension
can be closed (cyclic) or open.
MPI can help with establishing the mapping between ranks and Cartesian coordi-
nates in the process grid. First of all, a new communicator must be defined to which
the chosen topology is “attached.” This is done via the MPI_Cart_create()
function:
1 integer :: comm_old, ndims, dims(
*
), comm_cart, ierror
2 logical :: periods(
*
), reorder
3 call MPI_Cart_create(comm_old, ! input communicator
4 ndims, ! number of dimensions
5 dims, ! # of processes in each dim.
6 periods, ! periodicity per dimension
7 reorder, ! true = allow rank reordering
8 comm_cart, ! new cartesian communicator
9 ierror) ! return value
It generates a new, “Cartesian” communicator comm_cart, which can be used later
to refer to the topology. The periods array specifies which Cartesian directions are
periodic, and the reorder parameter allows, if true, for rank reordering so that the
rank of a process in communicators comm_old and comm_cart may differ. The
MPI library may choose a different ordering by using its knowledge about network
topology and anticipating that next-neighbor communication is often dominant in
a Cartesian topology. Of course, communication between any two processes is still
allowed in the Cartesian communicator.
There is no mention of the actual problem size (3000×4000) because it is entirely
the user’s job to care for data distribution. All MPI can do is keep track of the topol-
ogy information. For the topology shown in Figure 9.6, MPI_Cart_create()
could be called as follows:
1 call MPI_Cart_create(MPI_COMM_WORLD, ! standard communicator
2 2, ! two dimensions
3 (/ 4, 3 /), ! 4x3 grid
4 (/ .false., .true. /), ! open/periodic
5 .false., ! no rank reordering

222 Introduction to High Performance Computing for Scientists and Engineers
6 comm_cart, ! Cartesian communicator
7 ierror)
If the number of MPI processes is given, finding an “optimal” extension of the grid
in each direction (as needed in the dims argument to MPI_Cart_create())
requires some arithmetic, which can be offloaded to the MPI_Dims_create()
function:
1 integer :: nnodes, ndims, dims(
*
), ierror
2 call MPI_Dims_create(nnodes, ! number of nodes in grid
3 ndims, ! number of Cartesian dimensions
4 dims, ! input: /=0 # nodes fixed in this dir.
5 ! ==0 # calculate # nodes
6 ! output: number of nodes each dir.
7 ierror)
The dims array is both an input and an output parameter: Each entry in dims cor-
responds to a Cartesian dimension. A zero entry denotes a dimension for which
MPI_Dims_create() should calculate the number of processes, and a nonzero
entry specifies a fixed number of processes. Under those constraints, the function
determines a balanced distribution, with all ndims extensions as close together as
possible. This is optimal in terms of communication overhead only if the overall
problem grid is cubic. If this is not the case, the user is responsible for setting appro-
priate constraints, since MPI has no way to know the grid geometry.
Two service functions are responsible for the translation between Cartesian pro-
cess coordinates and an MPI rank. MPI_Cart_coords() calculates the Cartesian
coordinates for a given rank:
1 integer :: comm_cart, rank, maxdims, coords(
*
), ierror
2 call MPI_Cart_coords(comm_cart, ! Cartesian communicator
3 rank, ! process rank in comm_cart
4 maxdims, ! length of coords array
5 coords, ! return Cartesian coordinates
6 ierror)
(If rank reordering was allowed when producing comm_cart, a process should al-
ways obtain its rank by calling MPI_Comm_rank(comm_cart,...) first.) The
output array coords contains the Cartesian coordinates belonging to the process of
the specified rank.
This mapping function is needed whenever one deals with domain decomposi-
tion. The first information a process will obtain from MPI is its rank in the Cartesian
communicator. MPI_Cart_coords() is then required to determine the coordi-
nates so the process can calculate, e.g., which subdomain it should work on. See
Section 9.3 below for an example.
The reverse mapping, i.e., from Cartesian coordinates to an MPI rank, is per-
formed by MPI_Cart_rank():
1 integer :: comm_cart, coords(
*
), rank, ierror
2 call MPI_Cart_rank(comm_cart, ! Cartesian communicator
3 coords, ! Cartesian process coordinates
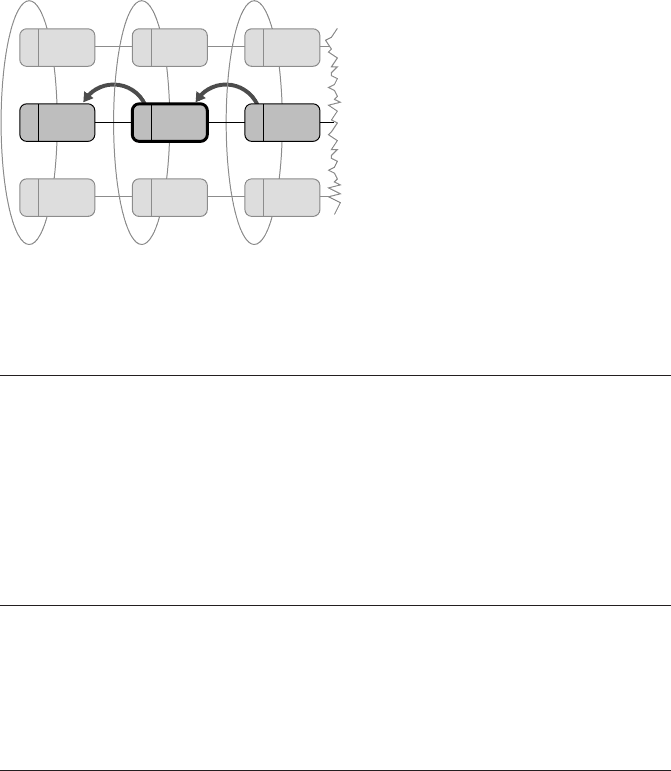
Distributed-memory parallel programming with MPI 223
7 (2,1)1 (0,1)
6 (2,0)3 (1,0)0 (0,0)
2 (0,2) 5 (1,2) 8 (2,2)
4 (1,1)
Figure 9.7: Example for the result of
MPI_Cart_shift() on a part of
the Cartesian topology from Figure 9.6.
Executed by rank 4 with direction=0
and disp=−1, the function returns
rank_source=7 and rank_dest=1.
4 rank, ! return process rank in comm_cart
5 ierror)
Again, the return value in rank is only valid in the comm_cart communicator if
reordering was allowed.
A regular task with domain decomposition is to find out who the next neigh-
bors of a certain process are along a certain Cartesian dimension. In principle one
could start from its Cartesian coordinates, offset one of them by one (accounting for
open or closed boundary conditions) and map the result back to an MPI rank via
MPI_Cart_rank(). The MPI_Cart_shift() function does it all in one step:
1 integer :: comm_cart, direction, disp, rank_source,
2 integer :: rank_dest, ierror
3 call MPI_Cart_shift(comm_cart, ! Cartesian communicator
4 direction, ! direction of shift (0..ndims-1)
5 disp, ! displacement
6 rank_source, ! return source rank
7 rank_dest, ! return destination rank
8 ierror)
The direction parameter specifies within which Cartesian dimension the shift
should be performed, and disp determines the distance and direction (positive or
negative). rank_source and rank_dest return the “neighboring” ranks, accord-
ing to the other arguments. Figure 9.7 shows an example for a shift along the negative
first dimension, executed on rank 4 in the topology given in Figure 9.6. The source
and destination neighbors are 7 and 1, respectively. If a neighbor does not exist be-
cause it would extend beyond the grid’s boundary in a noncyclic dimension, the rank
will be returned as the special value MPI_PROC_NULL. Using MPI_PROC_NULL
as a source or destination rank in any communication call is allowed and will effec-
tively render the call a dummy statement — no actual communication willtake place.
This can simplify programming because the boundaries of the grid do not have to be
treated in a special way (see Section 9.3 for an example).

224 Introduction to High Performance Computing for Scientists and Engineers
9.3 Example: MPI parallelization of a Jacobi solver
As a nontrivial example for virtual topologies and other MPI functionalities we
use a simple Jacobi solver (see Sections 3.3 and 6.2) in three dimensions. As opposed
to parallelization with OpenMP, where inserting a couple of directives was sufficient,
MPI parallelization by domain decomposition is much more complex.
9.3.1 MPI implementation
Although the basic algorithm was described in Section 5.2.1, we require some
more detail now. An annotated flowchart is shown in Figure 9.8. The central part is
still the sweep over all subdomains (step 3); this is where the computational effort
goes. However, each subdomain is handled by a different MPI process, which poses
two difficulties:
1. The convergence criterion is based on the maximum deviation between the
current and the next time step across all grid cells. This value can be easily
obtained for each subdomain separately, but a reduction is required to get a
global maximum.
2. In order for the sweep over a subdomain to yield the correct results, appropriate
boundary conditions must be implemented. This is no problem for cells that
actually neighbor real boundaries, but for cells adjacent to a domain cut, the
boundary condition changes from sweep to sweep: It is formed by the cells
that lie right across the cut, and those are not available directly because they
are owned by another MPI process. (With OpenMP, all data is always visible
by all threads, making access across “chunk boundaries” trivial.)
The first problem can be solved directly by an MPI_Allreduce() call after every
process has obtained the maximum deviation maxdelta in its own domain (step 4
in Figure 9.8).
As for the second problem, so-called ghost or halo layers are used to store copies
of the boundary information from neighboring domains. Since only a single ghost
layer per subdomain is required per domain cut, no additional memory must be al-
located because a boundary layer is needed anyway. (We will see below, however,
that some supplementary arrays may be necessary for technical reasons.) Before a
process sweeps over its subdomain, which involves updating the T = 1 array from
the T = 0 data, the T = 0 boundary values from its neighbors are obtained via MPI
and stored in the ghost cells (step 2 in Figure 9.8). In the following we will outline
the central parts of the Fortran implementation of this algorithm. The full code can
be downloaded from the book’s Web site.
2
For clarity, we will declare important
variables with each code snippet.
2
http://www.hpc.rrze.uni-erlangen.de/HPC4SE/