Фаулер М. Архитектура корпоративных программных приложений
Подождите немного. Документ загружается.


64 Часть I. Обзор
того, что необходимо знать для конструирования эффективного преобразователя данных,
на этом поприще от вас все еще потребуются значительные усилия. Поставщики ком-
мерческих инструментов, предназначенных для "связывания" объектно-ориентированных
приложений с реляционными базами данных, затратили многие годы на разрешение по-
добных проблем, и их программные продукты во многом более изобретательны, гибки и
мощны, нежели те, которые можно "состряпать" кустарным образом. Сразу оговорюсь,
что они недешевы, но затраты на их возможную покупку следует сопоставить со значи-
тельными расходами, которые вам придется понести, избрав путь самостоятельного соз-
дания и сопровождения этого слоя программного кода.
Нельзя не вспомнить о попытках разработки образцов слоя кода в стиле объектно-
ориентированных СУБД, способного взаимодействовать с реляционными системами.
В мире Java таким "зверем", например, является JDO, но о достоинствах или недостатках
этой технологии пока нельзя сказать ничего определенного. У меня слишком малый
опыт ее применения, чтобы приводить на страницах этой книги какие-либо категориче-
ские заключения.
Даже если вы решились на приобретение готовых инструментов, знакомство с пред-
ставленными здесь типовыми решениями вовсе не помешает. Хорошие инструменталь-
ные системы предлагают обширный арсенал альтернатив "подключения" объектов к ре-
ляционным базам данных, и компетентность в сфере типовых решений поможет вам
прийти к осмысленному выбору. Не думайте, что система в одночасье избавит вас от всех
проблем; чтобы заставить ее работать эффективно, вам придется приложить изрядные
усилия.
Функциональные проблемы
Когда речь заходит о взаимном отображении объектов и таблиц реляционной базы
данных, внимание обычно сосредоточивается на структурных аспектах, т.е. на том, как
следует соотносить таблицы и объекты. Однако я совершенно уверен, что самая трудная
часть проблемы — это выбор и обоснование архитектурной и функциональной состав-
ляющих.
Обсудив основные варианты архитектурных решений, рассмотрим функциональную
(поведенческую) сторону, в частности вопрос о том, как обеспечить загрузку различных
объектов и сохранение их в базе данных. На первый взгляд это не кажется слишком
сложной задачей: объект можно снабдить соответствующими методами загрузки ("load")
и сохранения ("save"). Именно такой путь целесообразно избрать, например, при ис-
пользовании решения активная запись (Active Record, 182).
Загружая в память большое количество объектов и модифицируя их, система должна
следить за тем, какие объекты подверглись изменению, и гарантировать сохранение их со-
держимого в базе данньпх. Если речь идет всего о нескольких записях, это просто. Но по ме-
ре увеличения числа объектов растут и проблемы: как быть, скажем, в такой далеко не
самой сложной ситуации, когда необходимо создать записи, которые должны ссылаться
на ключевые значения друг друга?
При выполнении операций считывания или изменения объектов система должна га-
рантировать, что состояние базы данных, с которым вы имеете дело, остается согласо-
ванным. Так, например, на результат загрузки данных не должны влиять изменения,

Глава 3. Объектные модели и реляционные базы данных 65
вносимые другими процессами. В противном случае итог операции окажется непредска-
зуемым. Подобные вопросы, относящиеся к дисциплине управления параллельными за-
даниями, весьма серьезны. Они обсуждаются в главе 5, "Управление параллельными
заданиями".
Типовым решением, имеющим существенное значение для преодоления такого рода
проблем, является единица работы (Unit of Work, 205), использование которой позволяет
отследить, какие объекты считываются и какие модифицируются, и обслужить операции
обновления содержимого базы данных. Автору прикладной программы нет нужды явно
вызывать методы сохранения — достаточно сообщить объекту единица работы о необхо-
димости фиксации (commit) результатов в базе данных. Типовое решение единица работы
упорядочивает все функции по взаимодействию с базой данных и сосредоточивает в од-
ном месте сложную логику фиксации. Его лучшие качества проявляются именно тогда,
когда интерфейс между приложением и базой данных становится особенно запутанным.
Решение единица работы удобно воспринимать в виде объекта, действующего как
контроллер процессов отображения объектов в реляционные структуры. В отсутствие та-
кового роль контроллера, принимающего решения о том, когда и как загружать и сохра-
нять объекты приложения, обычно выполняет слой бизнес-логики.
В процессе загрузки данных необходимо тщательно следить за тем, чтобы ни один из
объектов не был считан дважды, иначе в памяти будут созданы два объекта, соответст-
вующих одной и той же записи таблицы базы данных. Попробуйте обновить каждую из
них, и неприятности не заставят себя ждать. Чтобы уйти от проблем, необходимо вести
учет каждой считанной записи, а поможет в этом типовое решение коллекция объектов
(Identity Map, 216). Каждый раз при необходимости считывания порции данных вначале
следует проверить, не содержится ли она в коллекции объектов. Если информация уже
загружалась, можно предусмотреть возврат ссылки на нее. В этом случае любые попытки
изменения данных будут скоординированы. Еще одно преимущество — возможность из-
бежать дополнительного обращения к базе данных, поскольку коллекция объектов дейст-
вует как кэш-память. Не забывайте, однако, что главное назначение коллекции объек-
тов — учет идентификационных номеров объектов, а не повышение производительности
приложения.
При использовании модели предметной области (Domain Model, 140) связанные объек-
ты загружаются совместно таким образом, что операция считывания одного объекта
инициирует загрузку другого. Если связями охвачено много объектов, считывание лю-
бого из них приводит к необходимости загружать из базы данных целый граф объектов.
Чтобы исключить подобное неэффективное поведение системы, необходимо умерить
аппетит, сократив количество загружаемых объектов, но оставить за собой право завер-
шения операции, если потребность в дополнительной информации действительно воз-
никнет. Типовое решение загрузка по требованию (Lazy Load, 220) предполагает исполь-
зование специальных меток вместо ссылок на реальные объекты. Существует несколько
вариаций схемы, но во всех случаях реальный объект загружается только тогда, когда
предпринимается попытка проследовать по ссылке, которая его адресует. Решение за-
грузка по требованию позволяет оптимизировать число обращений к базе данных.

66 Часть I. Обзор
Считывание данных
Рассматривая проблему считывания информации из базы данных, я предпочитаю
трактовать предназначенные для этого методы в виде функций поиска (finders), скрываю-
щих посредством соответствующих входных интерфейсов SQL-выражения формата
"select". Примерами подобных методов могут служить find (id) или findForCus-
tomer (customer). Разумеется, если ваше приложение оперирует тремя десятками вы-
ражений "select" с различными критериями выбора, указанная схема становится черес-
чур громоздкой, но такие ситуации, к счастью, редки.
Принадлежность методов зависит от вида используемого интерфейсного типового
решения. Если каждый класс, обеспечивающий взаимодействие с базой данных, привя-
зан к определенной таблице, в его состав наряду с методами вставки и замены уместно
включить и методы поиска. Если же объект класса соответствует отдельной записи дан-
ных, требуется иной подход.
В этом случае можно попробовать сделать методы поиска статическими, но за это
придется заплатить некоторой долей гибкости, в частности вам более не удастся в целях
тестирования заменить базу данных фиктивной службой (Service Stub, 519). Чтобы избе-
жать подобных проблем, лучше предусмотреть специальные классы поиска, включив в
состав каждого из них методы, обеспечивающие инкапсуляцию тех или иных SQL-
запросов. В результате выполнения запроса метод возвращает коллекцию объектов, со-
ответствующих определенным записям данных.
Применяя методы поиска, следует помнить, что они выполняются в контексте со-
стояния базы данных, а не состояния объекта. Если после создания в памяти объектов-
записей данных, отвечающих некоторому критерию, вы активизируете запрос, который
предполагает поиск записей, удовлетворяющих тому же критерию, то очевидно, что объ-
екты, созданные, но не зафиксированные в базе данных, в результат обработки запроса
не попадут.
При считывании данных проблемы производительности могут приобретать первосте-
пенное значение. Необходимо помнить несколько эмпирических правил.
Старайтесь при каждом обращении к базе данных извлекать немного больше записей,
чем нужно. В частности, не выполняйте один и тот же запрос повторно для приобретения
дополнительной информации. Почти всегда предпочтительнее получить как можно
больше данных, но нужно отдавать себе отчет в том, что при использовании пессимисти-
ческой стратегии управления параллельными заданиями это может привести к ненужно-
му блокированию большого количества записей. Например, если необходимо найти
50 записей, удовлетворяющих определенному условию, лучше выполнить запрос, воз-
вращающий 200 записей, и применить для отбора искомых дополнительную логику, чем
инициировать 50 отдельных запросов.
Другой способ исключить необходимость неоднократного обращения к базе дан-
ных связан с применением операторов соединения (join), позволяющих с помощью од-
ного запроса извлечь информацию из нескольких таблиц. Итоговый набор записей
может содержать больше информации, чем требуется, но скорость его получения, ве-
роятно, выше, чем в случае выполнения нескольких запросов, возвращающих в ре-
зультате те же данные. Для этого следует воспользоваться шлюзом (Gateway, 483), охва-
тывающим информацию из нескольких таблиц, которые подлежат соединению, или
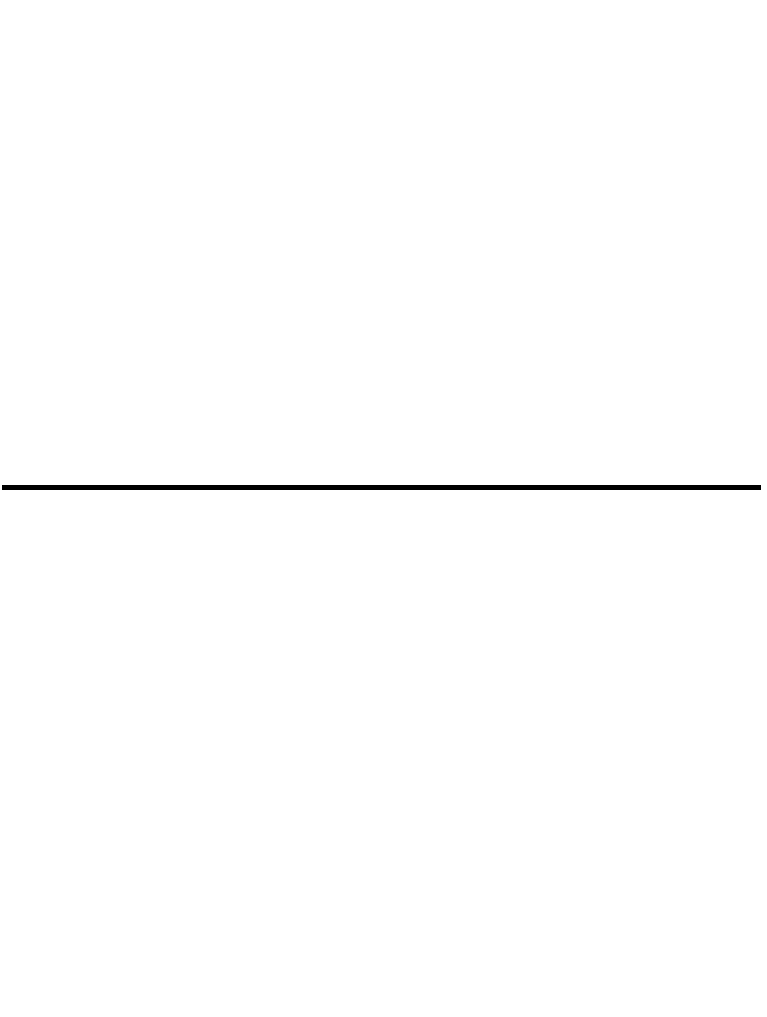
Глава 3. Объектные модели и реляционные базы данных 67
преобразователем данных (Data Mapper, 187), позволяющим загрузить несколько объ-
ектов домена с помощью единственного вызова.
Применяя механизм соединения таблиц, имейте в виду, что СУБД способны эф-
фективно обслуживать запросы, в которых соединению подвергнуто не более трех-
четырех таблиц. В противном случае производительность системы существенно падает,
хотя воспрепятствовать этому, по меньшей мере частично, удается, например, с помо-
щью разумной стратегии кэширования представлений.
Работу СУБД можно оптимизировать самыми разными способами, включая ком-
пактное группирование взаимосвязанных данных, тщательное проектирование индек-
сов и кэширование порций информации в оперативной памяти. Все эти технологии,
однако, выбиваются из контекста книги (хотя должны быть присущи сфере профес-
сиональных интересов хорошего администратора баз данных).
Во всех случаях, тем не менее, следует учитывать особенности конкретных прило-
жений и базы данных. Наставления общего характера хороши до определенного мо-
мента, когда необходимо как-то организовать способ мышления, но реальные обстоя-
тельства всегда вносят свои коррективы. Достаточно часто СУБД и серверы приложе-
ний обладают сложными механизмами кэширования, затрудняющими дать хоть
сколько-нибудь точную оценку производительности приложения. Никакое правило не
обходится без исключений, так что тонкой настройки и доводки системы избежать не
удастся.
Взаимное отображение объектов и реляционных структур
Во всех разговорах об объектно-реляционном отображении обычно и прежде всего
имеется в виду обеспечение взаимно однозначного соответствия между объектами в па-
мяти и табличными структурами базы данных на диске. Подобные решения, как прави-
ло, не имеют ничего общего с вариантами шлюза таблицы данных (Table Data Gateway,
167) и находят ограниченное применение совместно с решениями типа шлюза записи
данных (Row Data Gateway, 175) и активной записи (Active Record, 182), хотя все они, веро-
ятно, окажутся востребованными в контексте преобразователя данных (Data Mapper, 187).
Отображение связей
Главная проблема, которая обсуждается в этом разделе, обусловлена тем, что связи
объектов и связи таблиц реализуются по-разному. Проблема имеет две стороны. Во-
первых, существуют различия в способах представления связей. Объекты манипулируют
связями, сохраняя ссылки в виде адресов памяти. В реляционных базах данных связь од-
ной таблицы с другой задается путем формирования соответствующего внешнего ключа
(foreign key). Во-вторых, с помощью структуры коллекции объект способен сохранить
мноэюество ссылок из одного поля на другие, тогда как правила нормализации таблиц ба-
зы данных допускают применение только однозначных ссылок. Все это приводит к расхо-
ждениям в структурах объектов и таблиц. Так, например, в объекте, представляющем
сущность "заказ", совершенно естественно предусмотреть коллекцию ссылок на объек-
ты, описывающие заказываемые товары, причем последним нет необходимости ссылаться
68 Часть I. Обзор
на "родительский" объект заказа. Но в схеме базы данных все обстоит иначе: запись в
таблице товаров должна содержать внешний ключ, указывающий на запись в таблице за-
казов, поскольку заказ не может иметь многозначного поля.
Чтобы решить проблему различий в способах представления связей, достаточно со-
хранять в составе объекта идентификаторы связанных с ним объектов-записей, исполь-
зуя типовое решение поле вдентификации (Identity Field, 237), а также обращаться к этим
значениям, если требуется прямое и обратное отображение объектов и ключей таблиц ба-
зы данных. Это довольно скучно, но вовсе не так трудно, если усвоить основные приемы.
При считывании информации из базы данных для перехода от идентификаторов записей
к объектам используется коллекция объектов (Identity Map, 216). Связи, задаваемой
внешним ключом, отвечает типовое решение отображение внешних ключей (Foreign Key
Mapping, 258), устанавливающее подходящую связь одного объекта с другим (рис. 3.5).
Если в коллекции объектов ключа нет, необходимо либо считать его из базы данных, либо
применить вариант загрузки по требованию (Lazy Load, 220). При сохранении информа-
ции объект фиксируется в таблице базы данных в виде записи с соответствующим клю-
чом, а все ссылки на другие объекты, если таковые существуют, заменяются значениями
полей идентификации этих объектов.
Рис. 3.5. Пример использования типового решения отображение внешних
ключей для реализации однозначной ссылки
Если объект способен содержать коллекцию ссылок, требуется более сложная вер-
сия отображения внешних ключей, пример которой представлен на рис. 3.6. В этом слу-
чае, чтобы отыскать все записи, содержащие идентификатор объекта-источника, необ-
ходимо выполнить дополнительный запрос (или воспользоваться решением загрузка по
требованию). Для каждой считанной записи, удовлетворяющей критерию поиска, соз-
дается соответствующий объект, и ссылка на него добавляется в коллекцию. Для со-
хранения коллекции следует обеспечить сохранение каждого объекта в ней, гарантируя
корректность значений внешних ключей. Операция может быть довольно сложной,
особенно в том случае, когда приходится отслеживать динамику добавления объектов в
коллекцию и их удаления. В крупных системах с подобной целью применяются подхо-
ды, основанные на метаданных (об этом речь идет несколько позже). Если объекты

Глава 3. Объектные модели и реляционные базы данных 69
коллекции не используются вне контекста ее владельца, для упрощения задачи можно
обратиться к типовому решению отображение зависимых объектов (Dependent
Mapping, 283).
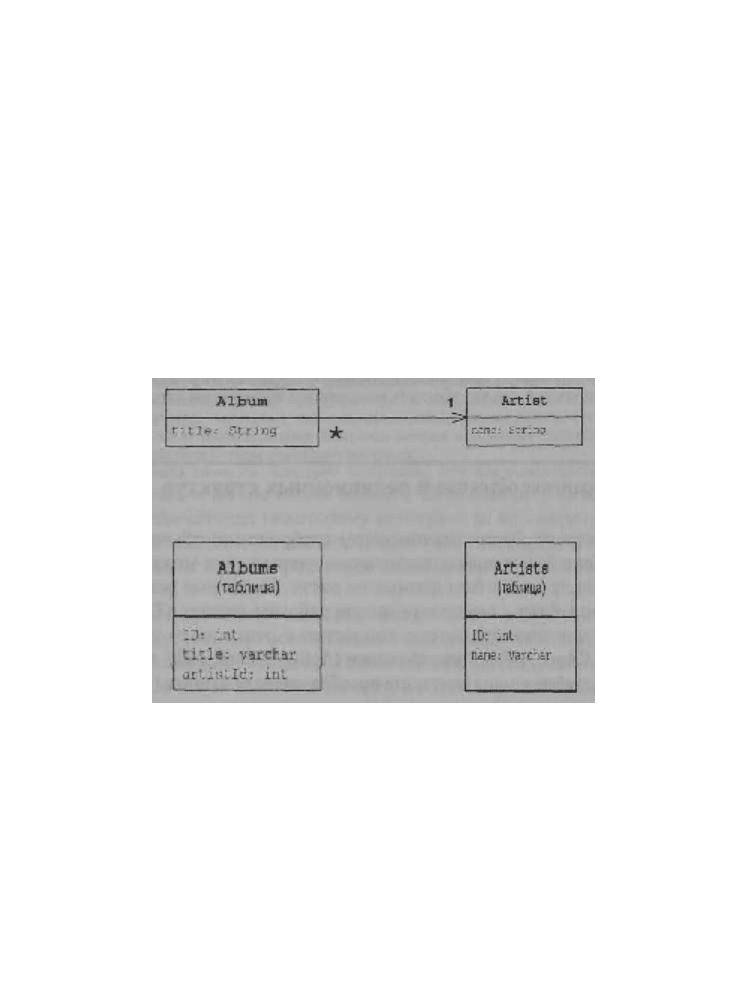
Рис. З.6. Пример использования типового решения отображение внешних
ключей для реализации коллекции ссылок
Совсем иная ситуация возникает, когда связь относится к категории "многие ко
многим", т.е. коллекции ссылок присутствуют "с обеих сторон" связи. Примером может
служить множество служащих и общий набор профессиональных качеств, отдельными из
которых обладает каждый служащий. В реляционных базах данных проблема описания
такой структуры преодолевается за счет создания дополнительной таблицы, содержащей
пары ключей связанных сущностей (именно это предусмотрено в типовом решении ото-
бражение с помощью таблицы ассоциаций (Association Table Mapping, 269)), пример кото-
рого показан на рис. 3.7.
Рис. 3.7. Пример использования типового решения отображение с помошью
таблицы ассоциаций для реализации связи "многие ко многим"

70 Часть I. Обзор
При работе с коллекциями принято полагаться на критерий упорядочения, с учетом
которого она создана. В объектно-ориентированных языках программирования обшей
практикой является использование типов упорядоченных коллекций, подобных спискам
и массивам. Однако задача сохранения в реляционной базе данных содержимого коллек-
ции с произвольным критерием упорядочения остается сложной. В качестве способов ее
решения можно порекомендовать использование неупорядоченных множеств или опре-
деление критерия упорядочения на этапе выполнения запроса к коллекции (последний
подход связан с большими затратами).
В некоторых случаях проблема обновления данных усугубляется из-за необходимости
выполнять условия целостности на уровне ссылок (referential integrity). Современные СУБД
позволяют откладывать (defer) проверку таких условий до завершения транзакции. Если
"ваша" система такую возможность предоставляет, грех ею не воспользоваться. Если нет,
система инициирует проверку после каждой операции записи. В такой ситуации вы обя-
заны соблюдать верный порядок прохождения операций. Не вдаваясь в детали, напомню,
что один из подходов связан с построением и анализом графа, описывающего такой по-
рядок, а другой состоит в задании жесткой схемы выполнения операций непосредственно
в коде приложения. Иногда это позволяет снизить вероятность возникновения ситуаций
взаимоблокировки (deadlock), для разрешения которых приходится осуществлять откат
(rollback) тех или иных транзакций.
Для описания связей между объектами, преобразуемых во внешние ключи, использу-
ется типовое решение поле идентификации, но далеко не все связи объектов следует фик-
сировать в базе данных именно таким образом. Разумеется, небольшие объекты-значения
(Value Object, 500), описывающие, скажем, диапазоны дат или денежные величины, не-
целесообразно представлять в отдельных таблицах базы данных. Объект-значение умест-
нее отображать в виде внедренного значения (Embedded Value, 288), т.е. набора полей объ-
екта, "владеющего" объектом-значением. При необходимости загрузки данных в память
объекты-значения можно легко создавать заново, не утруждая себя использованием кол-
лекции объектов. Сохранить объект-значение также несложно — достаточно зафиксиро-
вать значения его полей в таблице объекта-владельца.
Можно пойти дальше и предложить модель группирования объектов-значений с со-
хранением их в таблице базы данных в виде единого поля типа крупный сериализованный
объект (Serialized LOB, 292). Аббревиатура LOB происходит от словосочетания Large
OBject и означает "крупный объект"; различают крупные двоичные объекты (Binary
LOBs — BLOBs) и крупные символьные объекты (Character LOBs — CLOBs). Сериализация
множества объектов в виде XML-документа — очевидный способ сохранения иерархиче-
ских объектных структур. В этом случае для считывания исходных объектов будет доста-
точно одной операции. При выполнении большого количества запросов, предполагаю-
щих поиск мелких взаимосвязанных объектов (например, для построения диаграмм или
обработки счетов), производительность СУБД часто резко падает, и крупные сериализо-
ванные объекты позволяют существенно снизить загрузку системы.
Недостаток такого подхода состоит в том, что в рамках "чистого" SQL сконструировать за-
просы к отдельным элементам сохраненной структуры не удастся. На помощь может прийти
XML, позволяющий внедрить выражения формата XPath в вызовы SQL, хотя такой подход на
данный момент пока не стандартизован. Крупные сериализованные объекты лучше всего при-
менять для хранения относительно небольших групп объектов. Злоупотребление этим подхо-
дом приведет к тому, что база данных со временем будет напоминать файловую систему.
Глава 3. Объектные модели и реляционные базы данных 71
Наследование
Выше уже упоминались составные иерархические структуры, которые традиционно
плохо отображаются средствами реляционных систем баз данных. Существует и другая
разновидность иерархий, еще более усугубляющих страдания приверженцев реляцион-
ной модели: речь идет об иерархиях классов, создаваемых на основе механизма наследо-
вания (inheritance). Поскольку SQL не предоставляет стандартизованных инструментов
поддержки наследования, придется вновь прибегнуть к аппарату отображения. Сущест-
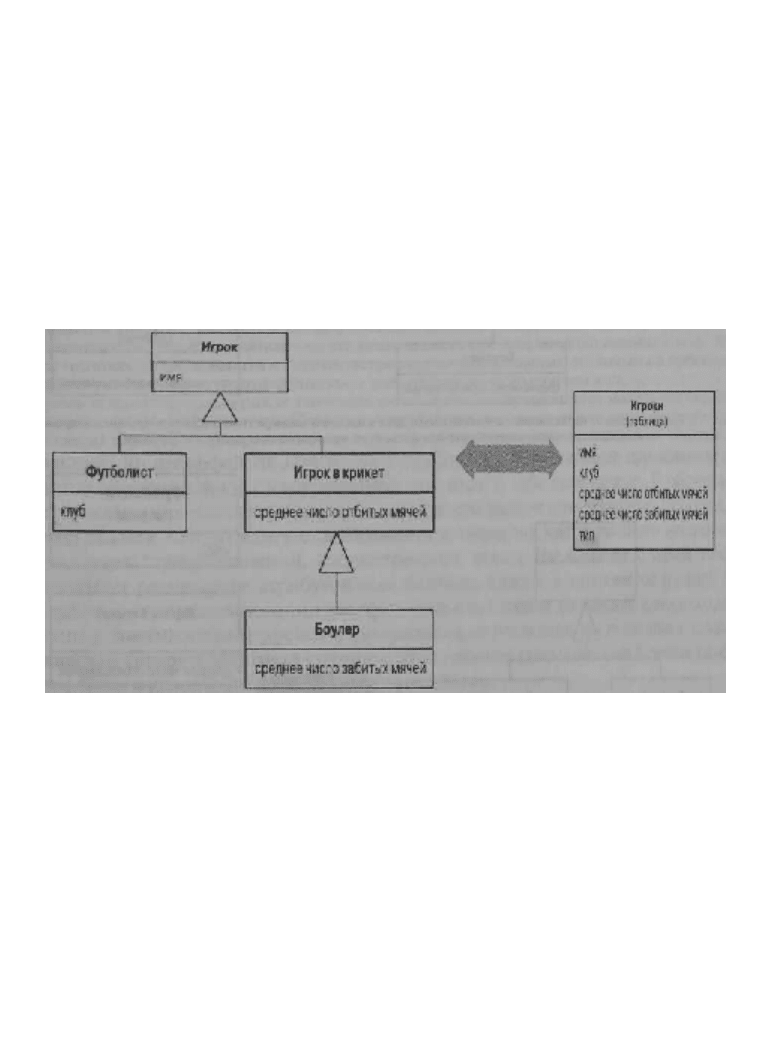
вует три основных варианта представления структуры наследования: "одна таблица для
всех классов иерархии" (наследование с одной таблицей (Single Table Inheritance, 297)) —
рис. 3.8; "таблица для каждого конкретного класса" (наследование с таблицами для каж-
дого конкретного класса (Concrete Table Inheritance, 313)) — рис. 3.9; "таблица для каждого
класса" (наследование с таблицами для каждого класса (Class Table Inheritance, 305)) —
рис. 3.10.
Рис. 3.8. Типовое решение наследование с одной таблицей предусматривает
сохранение значений атрибутов всех классов иерархии в одной таблице
Возможен компромисс между необходимостью дублирования элементов данных и по-
требностью в ускорении доступа к ним. Решение наследование с таблицами для каждого
класса — самый простой и прямолинейный вариант соответствия между классами и таб-
лицами базы данных, но для загрузки информации об отдельном объекте в этом случае
приходится осуществлять несколько операций соединения (join), что обычно сопряжено
со снижением производительности системы. Решение наследование с таблицами для каж-
дого конкретного класса позволяет обойти соединения, предоставляя возможность считы-
вания всех данных об объекте из единственной таблицы, но существенно препятствует
внесению изменений. При любой модификации базового класса нельзя забывать о необ-
ходимости соответствующего преобразования всех таблиц дочерних классов (и кода,
обеспечивающего корректное отображение). Изменение самой иерархической структуры
способно вызвать еще более серьезные проблемы. Помимо того, отсутствие таблицы для
базового класса может усложнить управление ключами. Что касается наследования с одной
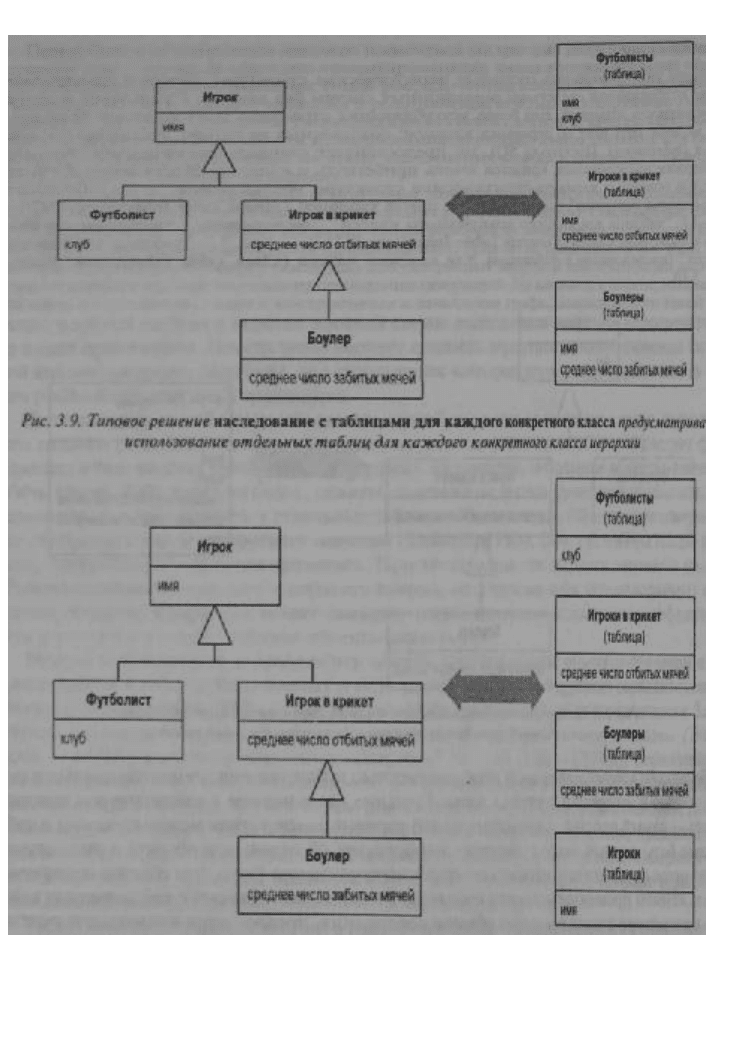
Рис. 3.10. Типовое решение наследование с таблицами для каждого класса предусматривает
использование отдельных таблиц для каждого класса иерархии
таблицей, то самым большим недостатком этого решения является нерациональное рас-
ходование дискового пространства, поскольку каждая запись таблицы содержит поля для
атрибутов всех созданных дочерних классов и многие из этих полей остаются пустыми.
72 Часть I. Обзор
Глава 3. Объектные модели и реляционные базы данных 73
(Впрочем, некоторые СУБД "умеют" осуществлять сжатие неиспользуемых областей.)
Большой размер записи приводит и к замедлению ее загрузки. Преимущество же насле-
дования с одной таблицей заключается в том, что все данные, относящиеся к любому
классу, сосредоточены в одном месте, а это значительно упрощает возможность внесения
изменений и позволяет избежать операций соединения.
Три упомянутых решения не являются взаимоисключающими — их вполне можно
сочетать в рамках одной и той же иерархии классов: например, информацию о наиболее
важных классах уместно объединить посредством наследования с одной таблицей, а для
других классов воспользоваться решением наследование с таблицами для каждого класса.
Разумеется, совмещение решений повышает сложность их применения.
Среди названных способов отображения иерархии наследования трудно выделить ка-
кой-либо один. Как и при использовании всех других типовых решений, необходимо
принять во внимание конкретные обстоятельства и требования. Моим первым выбором
был бы вариант наследования с одной таблицей как наиболее простой в реализации и ус-
тойчивый к многочисленным модификациям, а двумя другими я пользовался бы по мере
необходимости, чтобы избавиться от неподходящих или заведомо лишних полей. Лучше
всего, однако, побеседовать с администратором базы данных, знакомым со всеми ее ню-
ансами и тонкостями, и прислушаться к советам, которые он вам даст.
Здесь и далее в примерах и типовых решениях подразумевается модель единичного на-
следования (single inheritance). Сегодня парадигма множественного наследования (multiple
inheritance) теряет популярность и во многих языках все чаще изымается из обихода. При
использовании интерфейсов Java и .NET проблемы, сопутствующие применению инст-
рументов множественного наследования, все еще о себе напоминают. В обсуждаемых
здесь типовых решениях подобные аспекты специально не оговариваются. Впрочем, дос-
таточно сказать, что поладить с отображением иерархий множественного наследования
вам поможет "трио" решений, рассмотренных выше. Наследование с одной таблицей
предполагает размещение атрибутов всех базовых классов и интерфейсов в одной боль-
шой таблице, при использовании наследования с таблицами для каждого класса создаются
таблицы для каждого интерфейса и суперкласса, а реализация наследования с таблицами
для каждого конкретного класса связана с включением данных обо всех базовых классах и
интерфейсах в каждую таблицу конкретного класса.
Реализация отображения
Отображение объектов в реляционные структуры, по существу, сводится к одной из
трех общих ситуаций:
• готовой схемы базы данных нет, и ее можно выбирать;
• приходится работать с существующей схемой, которую не разрешается изменять;
• схема задана, но возможность ее модификации оговаривается дополнительно.
В простейшем случае, когда схема создается самостоятельно, а бизнес-логика отличает-
ся умеренной сложностью, оправдан подход, основанный на сценарии транзакции (Tran-
saction Script, 133) или модуле таблицы (Table Module, 148); таблицы могут создаваться