Энтропия и информация текстов
Подождите немного. Документ загружается.

12
ожидание информации, которое несет сигнал с m состояниями, каждое из
которых имеет вероятность появления р
i
.[3]
Энтропия позволяет сравнивать количества информации, приносимые
различными сигналами.
Знак минус в формуле не означает, что энтропия - отрицательная
величина. Объясняется это тем, что p
i
<1 по определению, а логарифм числа
меньшего единицы - величина отрицательная. По свойству логарифма,
поэтому эту формулу можно записать и во втором варианте, без минуса
перед знаком суммы.
Краткая справка о понятии логарифма и о свойствах логарифма
приведены в Приложении 10
Пример: В первой урне имеются 7 белых, 5 черных и 2 синих шара. Во
второй урне - 4 белых, 6 черных и 2 синих шара. Наудачу вынимают один
шар.d Для какой из урн исход более определенный?
Вычислим энтропию для каждого из случаев: шар – из первой урны,
шар – из второй урны. Менее определенному исходу соответствует большее
значение энтропии.
Для первой урны возможны три состояния: шар может оказаться или
белым, или черным, или синим.
Найдем вероятность каждого состояния: белый шар - р =7/14=1/2;
черный шар – р = 5/14; синий шар -ddd р = 2/14 =1/7.
Энтропия для первой урны:
H =
43,1)
7
1
log
7
1
14
5
log
14
5
2
1
log
2
1
(
бит
Аналогичные расчеты выполним для второй урны. Вероятности
состояний: белый шар - р =4/12= 1/3; черный шар – р = 6/12 =1/2; синий шар
-ddd р = 2/12 =1/6.
Энтропия для второй урны:
H =
41,1)
6
1
log
6
1
2
1
log
2
1
3
1
log
3
1
(
бит
d Так как энтропияd для второй урны меньше, значит исход для нее
более определенный (получено меньшее количество информации). [4]d
2.2 Основные свойства энтропии
Основные свойства энтропии заключаются в том, что
1. H≥0
2. H≤log
2
N, где N – количество равновероятных событий
Рассмотрим ситуацию, когда все варианты событий равновероятны,
остается зависимость только от количества вариантов, т.е. H=F(N). Отсюда
следует, что чем больше количество альтернатив (N), тем больше
неопределенность (H)
В этом случае используется формула, которая впервые была
предложена американским инженером Ральфом Хартли в 1928 году.

13
Формула хартли
H = log
2
N где H-энтропия информации; N - число возможных
(ожидаемых) сообщений.
Эти величины связаны в формуле не линейно, а через двоичный
логарифм. Логарифмирование по основанию 2 и приводит количество
вариантов к единицам измерения информации - битам.
Энтропия будет являться целым числом лишь в том случае, если N
является степенью числа 2, т.е. если N принадлежит ряду: {1, 2, 4, 8, 16, 32,
64, 128, 256, 512, 1024, 2048…}
Для решения обратных задач, когда известна неопределенность (H) или
полученное в результате ее снятия количество информации (I) и нужно
определить какое количество равновероятных альтернатив соответствует
возникновению этой неопределенности, используют обратную формулу
Хартли, которая выводится в соответствии с определением логарифма и
выглядит еще проще:
N=2
H
Формула Шеннона
В общем случае, энтропия H и количество получаемой в результате
снятия неопределенности информации I зависят от исходного количества
рассматриваемых вариантов N и априорных вероятностей реализации
каждого из них P: {p
0
, p
1
, …p
N-1
}, т.е. H=F(N, P). Расчет энтропии в этом
случае производится по формуле Шеннона, предложенной им в 1948 году в
статье «Математическая теория связи» (через 20 лет после Хартли).
При получении дополнительных сведений априорное максимальное
значение энтропии уменьшается, или снимается.
Рассмотрим это на примере опыта с колодой из 36 карт.
Пусть некто вынимает одну карту из колоды. Нас интересует, какую
именно из 36 карт он вынул. Изначальная неопределенность, рассчитываемая
по формуле (2), составляет H=log
2
(36)5,17 бит. Вытянувший карту сообщает
нам часть информации. Используя формулу (5), определим, какое количество
информации мы получаем из этих сообщений:
Вариант A. “Это карта красной масти”.
I=log
2
(36/18)=log
2
(2)=1 бит (красных карт в колоде половина,
неопределенность уменьшилась в 2 раза).
Вариант B. “Это карта пиковой масти”.
I=log
2
(36/9)=log
2
(4)=2 бита (пиковые карты составляют четверть
колоды, неопределенность уменьшилась в 4 раза).
Вариант С. “Это одна из старших карт: валет, дама, король или туз”.
I=log
2
(36)-log
2
(16)=5,17-4=1,17 бита (неопределенность уменьшилась
больше чем в два раза, поэтому полученное количество информации больше
одного бита).
Вариант D. “Это одна карта из колоды".
I=log
2
(36/36)=log
2
(1)=0 бит (неопределенность не уменьшилась -
сообщение не информативно).
Вариант D. “Это дама пик".

14
I=log
2
(36/1)=log
2
(36)=5,17 бит (неопределенность полностью снята).
3. Энтропия естественных языков
3.1 Энтропия языка
Шеннон ввел понятие энтропии как меры информации и получил
возможность работать с информацией — в первую очередь ее измерять и
оценивать такие характеристики, как пропускная способность каналов или
оптимальность кодирования. Но главным допущением было предположение,
что порождение информации — это случайный процесс, который можно
описать в терминах теории вероятностей. Если процесс не случайный — то
есть он подчиняется устойчивым закономерностям, то к нему, вообще
говоря, рассуждения Шеннона неприменимы. Все, что говорит Шеннон,
никак не связано с осмысленностью информации.
В реальном языке буквы не равновероятны (например, в английском
языке буква E встречается с большей вероятностью, чем Q). Используя
относительные частоты различных букв для вычисления энтропии
английского языка, мы получили бы оценку около 4,03 бита на букву. Таков
был бы коэффициент энтропии, если бы буквы алфавита встречались
независимо друг от друга. Но это не так.
При передаче символов в сообщении вероятность последующего
символа связанна с предыдущим символом и определяется смыслом
передаваемого сообщения. Например, за буквой Q почти всегда следует U, и
т.д. В связи с этими учет взаимосвязи в последующих символах приводит к
уменьшению энтропии.
Воспользовавшись условными распределениями, мы могли бы
построить более точную оценку коэффициента энтропии английского языка.
Неопределенность условного распределения символов
)/( AAH
не
может превышать энтропии их безусловного распределения
)(AH
.
)()/( AHAAH
Если воспользоваться моделью, в которой каждая буква зависит только
от предыдущей, то получится оценка примерно в 3,3 бита на букву.
Рассматривая распределение букв, которое зависит от трех предыдущих
букв, мы получаем оценку примерно в 2,8 бита на букву.
Однако всю сложность зависимостей, существующих в реальном
английском языке, ни одна из этих моделей полностью не передает.
Рассмотрим механизм вычисления энтропии языка.
Пусть источник s (l) порождает слова естественного языка l .
Допустим, что каждое слово в языке l состоит из k символов. По теореме
Шеннона величина h(s (l)) представляет собой минимальное среднее число
бит в сообщении, порожденном источником s (l) (сообщение этого
источника представляет собой слово, состоящее из k символов)
Поэтому величина

15
H =
K
LSH ))((
является минимальным средним количеством битов, необходимых для
записи символов языка L. Величина H называется энтропией языка L. Пусть
L – английский язык. Шеннон показал, что энтропия английского языка
составляет от 1 до 1,5 бит/на букву.
Следует иметь в виду, что, определяя количество информации в
сообщениях мы учитываем только статистику появления отдельных
символов алфавита и их сочетаний и не затрагиваем семантические и
прагматические аспекты информации.
Пусть ∑ =
zba ...,
. Тогда H
0
=
m
i
ii
pp
1
log
=log
2
26≈4,7 бит/буква.
Величина H называется абсолютной энтропией языка с алфавитом ∑.
Сравнивая величины H и H
0
, можно убедится, что фактическая
энтропия языка значительно меньше абсолютной. Это разность называется
избыточностью языка.
3.2 Энтропия русского языка
d Пусть сообщение — осмысленное предложение на русском языке.
При передаче различных букв мы передаем разное количество информации.
Если мы передаем часто встречающиеся буквы, то информация меньше; при
передаче редких букв — больше. Это видно при кодировании букв алфавита
азбукой Морзе. Наиболее частые буквы передаются коротко, а для редких
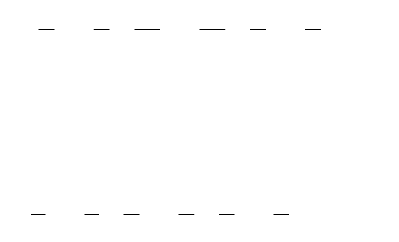
используют более длинные цепочки. Так, буква «Е» кодируется одной точкой
«
.
», а редкая «Ш» — четырьмя тире «– – – –» (это самая длинная
последовательность на букву в азбуке Морзе).
Предположим, что источник сообщения передает предложение
реального языка. Каждый следующий символ не полностью случаен, иd
вероятность его появления не полностью предопределена средней частотой
символа во всех сообщениях языка. То, какой символ последует дальше,
зависит от символов, уже переданных. Например, в русском языке после
символа «Ъ» не может идти символ согласного звука. После двух подряд
гласных «Е» третий гласный «Е» следует крайне редко (например, в слове
«длинношеее»). Таким образом, каждый следующий символ в некоторой
степени предопределен, поэтому мы говорим говорить об условной энтропии
символа.
Источник может порождать сообщения строго определенного типа —
например, формальную деловую переписку; в таком случае
предопределенность следующего символа может быть намного выше, чем в
среднем в языке. Тогда энтропия этого источника будет отличаться от
максимальной: она будет меньше. Если мы сравним энтропию конкретного
источника и максимальную энтропию, то определим избыточность
сообщения.
16
3.3 Оценка информации в тексте
Проделаем следующий опыт, предложенный в [1]. На 32 карточках
выпишем все буквы русского алфавита. После тщательного перемешивания
карт их извлечём наугад, запишем букву, возвращаем карту в коробку, снова
перемешиваем, извлекаем карту, записываем букву и т.д. Проделав такую
процедуру с вытаскиванием карточек 30 -50 раз, получим набор букв.
Нами была получена фраза: «Унфъжёяи ъйью ёддробо
ятуяптледепотлю»
Математик Р. Добрушин в результате такого эксперимента получил
набор букв, приведенный в первой строке табл. 1.
Таблица 1
Фразы Фраза Условия получения фразы
1
Сухерробьдщ Яыхвуи
Юайжтлфвнзагфо
Енвштур Пхгбкучтжю
Рямчьйхрыс
Равная вероятность
всех букв алфавита и
интервала между
словами
2
Еынт Уиябьа Оерв
Однг
Ьуемлолйкзбя Евнтша
Учтены вероятности
отдельных букв и пробелов
между словами
3
Весел Враться Не
Сухом
И Непо И Корко
Учтены вероятности
4-х буквенных
сочетаний
4
Теория Информации
Позволяет Изучить
Это Свойство
Реальных
Соблюдены реальные
вероятности сочетания
всех букв
Чередование букв беспорядочно, хаотично. Энтропия текста велика. По
предложенной методике вероятность извлечения любой из букв одинакова, т.
е.
W
A
= W
Б
= ... =W
Я
= 1/32
Вероятность извлечения пустой карточки (промежуток между словами)
также равна 1/32: на 32 буквы в среднем выпадает один интервал.
Энтропия появления каждой следующей буквы в тексте
подсчитывается по формуле Шеннона
I=
ßi
Ài
ßßÁÁAAii
WWWWWWWW )log...loglog(log
2222
Если вероятности появления букв одинаковы W
А
= W
Б
= ... = W
Я
, то
получаем энтропию I~5 бит.
17
В реальных текстах частота появления каждой буквы и интервалы
различны. В табл. 2 приведены частоты W
i
букв в русском языке. Из-за
неодинаковой вероятности появления различных букв в реальных текстах их
энтропия меньше, чем в первом опыте. Во втором опыте в коробку
помещается уже не 32 карточки, а больше: число карточек пропорционально
вероятностям появления букв. Например, на 1 карточку с буквой Ф (W
Ф
=
0,002) приходится 45 карточек с буквой О (W
О
= 0,090). Затем, как и в первом
опыте, идет вытаскивание и возвращение карточек. В результате появляется
фраза 2 (табл. 1), которая более упорядочена.
Таблица 2
Частота букв W
i
в русском языке
Пробел 0,175 Р 0,040 Я 0,018 Х 0,009
О 0,090 В 0,038 Ы 0,016 Ж 0,007
Е,Ё 0,072 Л 0035 З 0,016 Ю 0,006
А 0,062 К 0,028 Ь,Ъ 0,014 Ш 0,006
И 0,062 М 0,026 Б 0,014 Ц 0,003
Т 0,053 Д 0,025 П 0,013 Щ 0,003
Н 0,053 Г 0,023 Ч 0,012 Э 0,003
С 0,045 У 0,021 Й 0,010 Ф 0,002
Проанализируем полученные фразы
Во-первых, после учёта вероятности отдельных букв и сочетаний
(фраза 2 и 3)исчезли несуразно длинные слова.
Во-вторых, во фразе 2 гласные и согласные чередуются более
равномерно, но, тем не менее, не все можно даже прочитать, не говоря уже о
смысле.
Подставим в формулу Шеннона вероятность появления отдельных букв
I
1
= - 0,175 log
2
0,175 - 0,090 log
2
0,090 - ... - 0,002 log
2
0,002 = 4,35 бит.
Количество информации в сообщении, приходящейся на одну букву,
уменьшилось, с 5 до 4,35 бит, т. к. мы располагаем сведениями о частотах
встречаемости букв.
Но в языке существует частотный словарь, где учтены не только
частоты отдельных букв, но и их сочетаний (парных, тройных и т. д.). Если
учесть вероятность 4-х буквенных сочетаний в русском тексте, то получим
фразу 3 (табл. 1).
По мере учета все более протяженных корреляций возрастает сходство
полученных "текстов" с русским языком, но до смысла все еще далеко.
18
4. Анализ текстов различной специфики
Проиллюстрируем предложенные понятия и формулы на примере
вычислений, осуществляемых над текстами различных стилей и объёмов( не
менее 1000 символов). Для этого проведём анализ текстов по частоте
встречаемости букв, так как для русского языка мало опубликованных
данных такого рода.
Поскольку исследуемые характеристики принадлежат не только языку
как таковому, но зависят ещё от многих факторов, то следует исследовать
различные виды источников.
Первый источник представляет собой файл, полученный слиянием
нескольких файлов, содержавших текст учебников по философии.
Специфика текстов позволяет получить самые разнообразные буквенные
сочетания и вероятность букв. Объём документа 3,703 Мб
Фрагмент текста и результаты обработки приведены в Приложении 1
Вывод по первому источнику: обработка текста показала, что пробел ,
буквы О, Е, И, Н, Т, А, С встречаются чаще других. Почти отсутствуют
буквы Э, Ш, Ф, Ъ, Ё. Практически одинаковую частоту встречаемости
имеют такие буквы, как Т и А (Т = 0.0574725, А = 0.0571118) В и Р (В =
0.0392501,Р =.0388134 ), Ь и Б ( Ь = 0.0128209, Б = 0.0120790), Э и Ш (Э =
0.0038804, Ш = 0.0037972)
Количество информации на одну букву в тексте
I= 4,3562652
Второй источник так же является файлом, созданным путём слияния
различных текстовых документов (рассматривается художественная
литература). Частота встречаемости букв характерна для наиболее часто
употребимых слов, выражений и т.д.
Объём документа 947 Кб.
Фрагмент текста и результаты обработки приведены в Приложении 2
Вывод по второму источнику: обработка текста показала, что пробел ,
буквы О, Е, А, Т, Н, И, С встречаются чаще других. Почти отсутствуют
буквы Щ, Э, Ф, Ъ, Ё. Практически одинаковую частоту встречаемости
имеют такие буквы, как Н и И ( Н = 0.0345210 И = 0.0332279) , Д и М (Д =
0.0183750,М = 0.0180478), Ы и Г (Ы = 0.0102668, Г = 0.0100300)
Количество информации на одну букву в тексте
I= 3,3902703
Третий источник составлен из сказок различных писателей. Характер
текстов позволяет проследить наиболее часто употребляемые буквы.
Объём документа 1,46 мб.
Фрагмент текста и результаты обработки приведены в Приложении 3
Вывод по третьему источнику : обработка текста показала, что пробел ,
буквы О, А, Е, И, Т, Н, Л встречаются чаще других. Почти отсутствуют
буквы Щ, Э, Ф, Ъ, Ё. Практически одинаковую частоту встречаемости
имеют такие буквы, как Н и Л (Н = 0,0438128261831048 Л =
0,0434731534719151), Р и В (Р = 0,0357901813356922, В =
19
0,0352948252985405), Ы и Б (Ы = 0,0146250331711632, Б =
0,014565590446705 )
Количество информации на одну букву в тексте
I = 4,2957078
Также составим четвёртый документ, который будет представлять
собой соединение всех предыдущих для того, что бы проследить
достоверность полученных результатов в независимости от специфики
текста.
Объём документа 6 Мб.
Результаты обработки приведены в Приложении 4
Вывод по четвёртому источнику : обработка текста показала, что
пробел , буквы О, Е, И, А, Н, Т, С встречаются чаще других. Почти
отсутствуют буквы Щ, Э, Ф, Ъ, Ё. Практически одинаковую частоту
встречаемости имеют такие буквы, как Р и В (В = 0.0388497, Р = 0.0384732),
Я и У (Я = 0185945 У = 0.0184885), Ч , Б и Г (Ч = 0.0129143,Б = 0.0122163, Г
=0.0120483)
Количество информации на одну букву в тексте
I = 4,2676604
Сравним полученные результаты с показаниями, полученными путём
теоретических расчётов.
Первый источник
Таблица вычисленных частот для первого текста и
среднестатистических частот в сопоставлении дана в Приложении 5
При обработке первого источника нами были получены результаты,
которые почти соотносятся со среднестатистическими показателями
относительной частоты букв, однако есть различия. Практически ни одна из
полученных нами частот не совпадает полностью со среднестатистической,
за исключением букв О, В, Л, К, Д, П, Ы, Ж, Э (различия между
полученными нами показателями можно считать не существенными, когда
разница составляет несколько сотых). Столь существенные отклонения
могут объясняться спецификой текста и небольшим объёмом источника.
Второй источник
Таблица вычисленных частот для второго текста и
среднестатистических частот в сопоставлении дана в Приложении 6
Полученные результаты очень сильно отличаются от
среднестатистических показателей относительной частоты букв. Ни одна из
полученных нами частот не совпадает со среднестатистической. Однако
порядок убывания частот букв в первом источнике почти совпадает с
порядком убывания относительных среднестатистических частот.
Обнаруженные нами различия также можно объяснить спецификой текста и
небольшим объёмом источника
Третий источник
Таблица вычисленных частот для третьего текста и
среднестатистических частот в сопоставлении дана в Приложении 7
20
Полученные результаты отличаются от среднестатистических
показателей относительной частоты букв. Но некоторые буквы имеют
частоту сходную со среднестатистической (разница несколько сотых). Это
буквы С, В, Д, У, Ь, П, Я, Ы, Б, Г, Ч, Ж и т.д. Обнаруженные сходства и
различия частоты букв значительно меньше чем во втором источнике. Это
объясняется большим объёмом текста. Несмотря на специфику, полученные
нами значения в сопоставлении приближаются к значениям 1 источника и
среднестатистической относительной частоты.
Чётвёртый источник
Таблица вычисленных частот для второго текста и
среднестатистических частот в сопоставлении дана в Приложении 8
Полученные результаты практически не отличаются от
среднестатистических (различия не более нескольких сотых). Единственное
различие составляют буквы А и И. Порядок убывания частот (кроме букв А и
И) в исследуемом нами источнике идентичен порядку убывания
среднестатистических относительных частот букв. Такое сходство говорит о
том, что чем больше размер источника и разностороннее специфика, тем
достовернее полученные показания
Таким образом, на основе анализа различных текстов нами было
выяснено, что специфика текста и его объём существенно влияют на
сходство или различие со среднестатистическими данными. Чем больше
объём документа, тем ближе полученные результаты к усреднённым
показателям. Частота букв в последнем четвёртом источнике, имеющем
наибольший объём и составленном из текстов различной специфики,
практически совпадает со среднестатистической. Частота букв в небольших
по объёму текстах может как быть сходной со среднестатистической, так и
существенно отличаться от неё.
В результате исследования мы обнаружили, что количество
информации, содержащейся источнике зависит от его размера. Чем меньше
размер исследуемого текста, тем больше расхождение между показаниями
частот букв, полученными нами, и среднестатистическими: результаты
обработки меньше среднестатистических относительных частот. Поэтому и
информация, содержащаяся в данном тексте значительно меньше, чем в
других (Второй источник I = 3,3902703).
Сравним показания других трёх источников: Первый источник I =
4,3562652, Третий источник I= 4,2957078, Чётвёртый источник I =
4,2676604. Несмотря на то, что четвёртый источник самый большой по
размеру – 6 Мб, информация, находящаяся в нём, меньше, чем в первом или
третьем. Это объясняется тем, что данный текст содержит в себе второй
источник, и за счёт этого происходит «уменьшение» информации.
21
Заключение
Данная работа посвящена теме, актуальной в настоящее время в связи
с её разнообразными приложениями.
В ходе работы были рассмотрены основы теории информации
К.Шеннона. В свете данной теории были изучены различные подходы к
таким понятиям, как информация (I) и энтропия (H).
Кроме того, мы проследили связь между энтропией и информацией,
которая отражена в определении энтропии как снятой неопределённости и в
формуле её вычисления.
В ходе исследования нами было изучено понятие энтропии языка и
проведён анализ текстов, с точки зрения частоты встречаемости различных
букв в них.
Мы выяснили, что энтропия различных по специфике источников
отличается друг друга и от среднестатистических относительных частот
букв, взятой за образец.
Частота встречаемости букв в тексте, зависящая от размера
рассматриваемого источника, напрямую влияет на информацию,
содержащуюся в нём. Таким образом, нами была установлена зависимость
между информацией и размером источника.